Основой работы поисковых систем как Google, так и Яндекс является система кластеров. Вся информация делится на определенные области, которые относятся к тому или иному кластеру. Индексация сайтов с целью получения данных о размещенной на них информации выполняется роботами-сканерами. Существуют следующие виды сканирующих роботов: основной робот-сканер и робот-сканер, отвечающий за сбор информации на ресурсах с частым обновлением содержания. Второй тип сканирующего робота предназначен для быстрого обновления списка проиндексированных ресурсов и значения их индексов в поисковой системе. Для наиболее полного обеспечения сбора информации в системе Яндекс применяются обновления базы поиска и обновления программного кода:
- База поисковой информации обновляется несколько раз в течение месяца, при этом на поисковые запросы выдается обновленная информация с сайтов. Такая информация добавляется с помощью основного робота-сканера.
- При обновлении программного кода или «движка» выявляются недостатки и изменяются алгоритмы, отвечающие за ранжирование ресурсов в поисковой системе. Как правило, перед выходом таких обновлений Яндекс публикует соответствующие анонсы.
Основная особенность системы Яндекс, делающая популярной ее среди русскоязычных пользователей, – это способность определять различные словоформы с учетом морфологических особенностей русского языка. При этом значения запроса с помощью геотаргетинга и формул поиска преобразуется в максимально точную формулировку. Кроме того, Яндекс отличается алгоритмом по определению релевантности индексируемых страниц (релевантностью называют соотношение содержания веб-страницы к содержанию поискового запроса). Также к положительным сторонам можно отнести высокую скорость ответной реакции на запросы и устойчивую, без перегрузок, работу серверов.
Большое значение для поисковой системы имеют динамические ссылки, наличие которых может привести к отказу от индексации ресурса поисковым роботом.
В процессе индексации Яндекс распознает текстовую информацию в документах с расширениями: .pdf, .rtf, .doc, .xls, .ppt. Последние два относятся к программам входящими в комплект Microsoft Office: Excel и PowerPoint.
При индексировании сайта поисковая система считывает данные из файла robots.txt, при этом поддерживается атрибут Allow и часть метатегов, а метатеги Revisit-After и Keywords игнорируются.
Так как сниппеты – краткие описания текстовых документов – составляются из фраз на искомой странице, то использование описания в теге не является обязательным, но может использоваться в отдельных случаях.
По заявлениям разработчиков кодировка индексируемых документов определяется автоматически, а значит, и метатег кодировки не имеет большого значения.
Поисковая система большое значение придает показателю последнего изменения информации (Last-Modified). Если сервер не будет передавать эту информацию, то процесс индексации данного ресурса будет происходить намного реже.
Пока что остается нерешенной проблема страниц, использующих фреймовые структуры, но она может быть обойдена с помощью скриптов, отправляющих пользователей поисковой системы в нужное место сайта.
Если у сайта существуют «зеркала» (например, http://www.site.ru, http://site.ru, https://www.site.ru, https://www.site.ru), необходимо принять соответствующие действия для исключения их из процесса индексации. Если индексацию «зеркал» избежать не удалось, можно «склеить» их путем внесения необходимой информации в robots.txt.
В случае попадания сайтов в Яндекс.Каталог система будет идентифицировать их как заслуживающих отдельного внимания, что может повлиять на продвижение сайтов. Также это способствует упрощению процедуры определения тематики сайта, что в свою очередь означает получение сайтом значимой внешней ссылки.
Команда поисковой системы Яндекс держит в секрете IP-адреса своих роботов. Но в лог-файлах отдельных сайтов можно встретить текстовые пометки, оставленные поисковыми роботами Яндекс.
Одними из самых интересных роботов-сканеров поисковой системы Яндекс можно назвать:
- Yandex/1.01.001 (compatible; Win16; I) – основной робот, занимающийся непосредственно индексацией сайтов;
- Yandex/1.01.001 (compatible; Win16; P) – робот-индексатор изображений;
- Yandex/1.01.001 (compatible; Win16; H) – робот, который выявляет «зеркала» индексируемых сайтов;
- Yandex/1.02.000 (compatible; Win16; F) – робот-индексатор пиктограмм ресурсов (favicons);
- Yandex/1.03.003 (compatible; Win16; D) – робот, который обращается к страницам, добавленным с помощью формы «Добавить URL»;
- Yandex/1.03.000 (compatible; Win16; M) – задействуется при переходе на страницу посредством ссылки «Найденные слова»;
- YaDirectBot/1.0 (compatible; Win16; I) – этот робот отвечает за индексацию страниц ресурсов, принимающих участие в рекламной сети Яндекс.
Из всех поисковых роботов самый важный так и называется – основной поисковый робот. От того, как он проиндексирует страницы сайта, будет зависеть значимость ресурса для поисковой системы.
Работа всех роботов происходит по индивидуальному расписанию, и если сайт проиндексирован одним из них, то это не значит, что скоро будет произведена индексация и другим.
В помощь основным созданы и роботы, которые периодически посещают сайты и устанавливают, насколько те доступны. К таким можно отнести роботов «Яндекс.Каталога» и рекламной сети Яндекс.
Для поисковой системы Яндекс характерны следующие основные показатели внешней оптимизации:
- тИЦ – это общедоступный тематический индекс цитирования, он не оказывает прямого влияния на ранжирование и используется для определения позиций в тематической категории Яндекс.Каталога; применяется, когда необходима раскрутка сайта, тИЦ показывает, какое количество ссылок, в среднем, обращается к сайту.
- вИЦ, или взвешенный Индекс Цитирования, представляет собой алгоритм для подсчета количества внешних ссылок; значение его не разглашается и используется поисковой системой как определяющее при ранжировании сайтов в поисковой системе.
- Присутствие сайта в «Яндекс.Каталоге».
- Общее число страниц сайта, принявших участие в индексации.
- Частота, с которой индексируется содержимое сайта.
- Наличие и отсутствие ссылок с сайта, присутствие сайта в поисковых фильтрах.
Индекс цитирования создает основу для тематического и взвешенного индекса цитирования, которые влияют на ранжирование сайта.
Индекс цитирования (ИЦ) - это указатель цитирований (количества ссылок на источник) между публикациями, позволяющий узнать, какие из более поздних документов ссылаются на более ранние работы, при этом, ИЦ может рассматриваться как для отдельных статей, так и для авторов (ученных).
В поисковой системе Яндекс, а также в других поисковых системах, под индексом цитирования подразумевается количество обратных ссылок, без учета ссылок со следующих ресурсов: немодерируемых каталогов, досок объявлений, сетевых конференций, страниц серверной статистики, XSS ссылки и другие, которые могут добавляться без контроля со стороны владельца ресурса. Стоит отметить, что в каталоге Апорт под ИЦ понимается взвешенный индекс цитируемости.
Рассчитывается этот индекс из ссылочного графа: если рассматривать ресурсы сети как вершины графа, а цитирование других ресурсов (ссылочные связи между сайтами) как связи вершин графа (ребра), тогда ссылочный граф можно представить в виде диаграммы, как показано на рисунке 3.1.
Рисунок – Ссылочный граф
На рисунке буквами А, B, …, F обозначены определенные сайты в индексе поисковой системы, стрелки изображают направление связей - односторонние либо двусторонние.
ИЦ используется как один из факторов для ранжирования документов в поисковой выдаче, но не является главным.
Не стоит путать обычный индекс цитирования с взвешенным и тематическим, о которых будет написано позже. Индекс цитируемости всегда целое число и не зависит от тематик ссылающихся документов.
Индекс цитируемости обычно рассматривается в качестве параметра значимости статьи, однако он не отражает структуру ссылок в каждой дисциплине (тематике), а также слабозначимые работы и труды с большой значимостью могут иметь одинаковый индекс цитируемости.
Поэтому был введен взвешенный индекс цитирования, который определяется не только количеством, но и качеством ссылающихся источников. Введение ссылочного поиска и статической ссылочной популярности помогает поисковым системам справляться с примитивным текстовым спамом, который полностью разрушает традиционные статистические алгоритмы информационного поиска, полученные в свое время для контролируемых коллекций. ВИЦ является аналогом PageRank от Google.
Взвешенный индекс цитирования, как и другие ссылочные факторы ранжирования, рассчитывается из ссылочного графа. Узнать вИЦ для своих страниц вы можете приблизительно, проверив их PageRank любым онлайн-сервисом проверки, однако, следует учесть, что в индексе Яндекса присутствуют только русскоязычные документы, а из зарубежных лишь некоторые популярные, таким образом, урезая ссылочный граф по сравнению с Google.
Тематический индекс цитирования введен для отражения авторитетности сайта в своей тематике.
При определении тематики сайта сначала строится описание рассматриваемого ресурса (из названия категорий сайта, заголовков, структуры URL его страниц). Далее вычисляется оценка близости между описаниями заранее подготовленных тематик (каталог) и описаниями ресурсов с выбором наиболее близких тематик для них.
Тематическая близость двух документов отражает вероятность принадлежности их обоих одной и той же тематике. Этот показатель может влиять на значение передаваемого ссылкой веса.
Расчет тИЦ основан на формуле:

где PF(v,t) – тИЦ ресурса v;
P – количество ресурсов, которые ссылаются на сайт v и имеют ту же тематику;
n v – количество страниц на рассматриваемом сайте v;
N – общее число страниц в индексе Яндекса (при этом, n v /N - вероятность того, что пользователь читает сайт v);
w(i) – частота цитируемости ресурсом i сайта v;
N(i) – общее число ссылок на i-ом сайте.
При этом, PF(v,t) является нормализованной величиной.
Изначально тематический индекс цитирования отражал ситуацию в Рунете, но со временем индекс Яндекса расширился на такие географические сегменты, как Беларусь, Украина и другие. В Яндексе появились новые версии каталога для дополнительных регионов.
Соответственно, чтобы ранжировать сайты в каждом из региональных Яндекс.Каталогов, потребовалось ввести региональный тИЦ, который учитывает, помимо тематической, географическую близость ссылок.
Таким образом, тИЦ обладает следующими свойствами:
1. тИЦ зависит от количества уникальных страниц на сайте и чем их больше, тем больше результирующий показатель.
2. Чем меньше исходящих ссылок на сайте-доноре, тем больше с него передается тИЦ.
3. тИЦ никак не зависит от перелинковки.
4. Анкоры ссылок не участвуют в определении тематической близости двух ресурсов.
5. При наличии у сайта нескольких зеркал (копий), при их склейке результирующий тИЦ суммируется.
Браузер - это окно в интернет. Многие держат его открытым целыми днями: мимо него бежит лента новостей, в нём мы наблюдаем за жизнью наших друзей, к нему обращаемся, когда хотим что-то найти. Но интернет не всегда выглядел так, как мы привыкли. Вернее, долгое время он вообще никак не выглядел.
В браузере мы видим не интернет, а Всемирную паутину, или веб. Сам интернет - это инфраструктура, комплекс сетей, в которые объединены компьютеры по всему миру. А веб - способ наглядно представить хранящуюся на них информацию в виде связанных между собой страниц. На этих страницах могут быть текст, картинки, видеоролики, разнообразные кнопки, ссылки и многое другое. Чтобы все эти элементы работали и отображались корректно, страницу нужно открыть в специальной программе. Эта программа и есть браузер.
Немного истории
Прообраз современного веба и, соответственно, первый браузер появились в 1991 году в ЦЕРН - европейской организации по ядерным исследованиям. Один из её сотрудников, Тим Бернерс-Ли, придумал провязать научные документы гиперссылками и решить таким образом проблему поиска информации в огромном архиве института. Первый браузер назывался WorldWideWeb и выглядел примерно вот так.
Браузер WorldWideWeb в 1993 году. Источник - страница Тима Бернерса-Ли на w3.org
Там же, в ЦЕРН, появилась и первая веб-камера . Учёные, у которых была одна кофе-машина на несколько этажей, поставили рядом с ней камеру, которая несколько раз в минуту отправляла фотографии на их компьютеры - всё для того, чтобы можно было, не отрываясь от работы, узнать, есть ли в машине кофе.
В начале 90-х появились не только веб и первые браузеры - тогда же начинали работать первые коммерческие интернет-провайдеры. До этого интернет финансировался правительством и доступ в него был только в больших университетских центрах и военных организациях. Теперь же в сеть мог выйти любой человек с домашнего компьютера.
Интернет стал публичным, а с появлением веба и сравнительно простых в освоении браузеров вроде Mosaic и Netscape Navigator - ещё и наглядным. Из инструмента научного сообщества он постепенно стал превращаться в средство массовой коммуникации, а затем, с ростом аудитории, и в глобальную торгово-развлекательную площадку.
Последняя версия браузера Mosaic, выпущена в 1997 году. Источник - Википедия.
Сегодня сотни миллионов людей ежедневно ищут в сети информацию и новости, слушают музыку и смотрят фильмы, играют, общаются, покупают. Чтобы всё это стало возможным, браузерам пришлось многому научиться. Простейший пример - отображение нескольких страниц в одном окне. Вкладки стали появляться в популярных браузерах только в первой половине 2000-х - теперь же навигацию в сети без них трудно представить.
Из чего сделан Яндекс.Браузер
Первая версия Яндекс.Браузера была выпущена в 2012 году. Создавая его, мы использовали уже существующие наработки. Например, «движок» для нашего браузера мы выбрали такой же, как у Safari и Google Chrome - называется он WebKit. Чтобы объяснить, почему мы выбрали именно его, надо хотя бы в двух словах рассказать, что вообще делает движок.
Если коротко, то он собирает сайты по инструкции - примерно так же, как мы собираем мебель, которая приехала из магазина в нескольких коробках. Страницы сайтов становятся такими, какими мы привыкли их видеть, только на экране компьютера. Пока вы не смотрите на них через браузер, они существуют в виде документов со ссылками на «детали» (например, картинки, которые используются для фона и кнопок) и кодом, который определяет, как их надо соединить..
Это только маленькая часть кода страницы сайт - целиком он длиннее, чем вся эта статья.
У каждого движка есть свои особенности - именно поэтому один и тот же сайт может немного по-разному выглядеть в разных браузерах. Если создатель сайта не учитывает эти особенности, то какой-нибудь браузер может неправильно понять его инструкции и собрать что-то некрасивое или вообще неработающее. Мы не стали придумывать собственный «движок», чтобы разработчикам сайтов не приходилось адаптировать свои сайты ещё и под него. Вместо этого был выбран популярный WebKit, на который уже ориентируются большинство веб-разработчиков.
У WebKit есть несколько реализаций - наш браузер работает на той, что развивается в проекте Chromium. Им занимаются сразу несколько крупных компаний - причём ко всеобщей выгоде. Если одна компания придумывает какое-то техническое улучшение, от этого выигрывают все (если интересно, например, о том, как разработчики Яндекс.Браузера помогли значительно ускорить все программы на основе Chromium). Кроме того, это позволяет совместно продвигать современные веб-стандарты, то есть делать интернет удобнее и безопаснее.
Что делает Яндекс.Браузер особенным
Самый очевидный ответ - это дизайн. С самого начала мы старались сделать так, чтобы интерфейс не был громоздким. Наш идеал браузера - это не просто окно, а «панорамное окно» в интернет: во весь экран и с минимум деталей. Какое-то время мы вообще пробовали сделать прозрачный браузер - этот проект назывался Кусто. Тестирование показало, что далеко не все пользователи готовы к таким переменам, зато некоторые нововведения, вроде анимированных фонов и умной поисковой строки, многим пришлись по душе. В той версии Яндекс.Браузера, над которой мы работаем сейчас, лучшие идеи, опробованные в Кусто, сочетаются с классическими интерфейсными решениями. Теперь наш браузер выглядит вот так.
Это Яндекс.Браузер для Windows. Версии для Mac OS и Linux пока выглядят иначе.
Дизайн - это не только внешний вид, но и практичность. В Яндекс.Браузере есть много незаметных на первый взгляд решений, которые делают его удобным. Например, чтобы увидеть Табло со ссылками на часто посещаемые сайты, необязательно открывать новую вкладку, достаточно нажать на адресную строку. Благодаря этому путь до нужной страницы сокращается на один шаг.
Той же цели - сэкономить время и клики - служит нашего браузера. Используя данные Яндекса о популярных поисковых запросах, она может подсказать адрес нужного сайта, даже если вы на нём никогда не были, и предложить перейти на vk.com человеку, который забыл переключить раскладку и успел напечатать «млюс». На некоторые простые вопросы - вроде [курс доллара], [погода в самаре] или [формула объема шара] - Умная строка может ответить самостоятельно, так что пользователю даже не придётся переходить на новую страницу, чтобы получить информацию.
Другой пример продуманного дизайна тоже связан с адресной строкой. В она расположена внизу экрана, а не наверху, как у большинства браузеров, - просто потому что так до неё удобнее дотянуться большим пальцем. Экраны смарфтонов становятся всё больше, а наши пальцы пока не удлиняются, вот и приходится с этим считаться.
Ещё одна особенность нашего браузера состоит в том, что он сам ищет для вас интересную информацию. Открыв новую вкладку, вы увидите внизу блок, озаглавленный «Дзен: ваши персональные рекомендации». В нём собираются статьи и видео на темы, которыми вы обычно интересуетесь. Уникальность в том, что за составление ленты публикаций отвечает машинный интеллект : он собирает их не из тематических RSS-подборок, а со всего интернета - с помощью поисковых технологий Яндекса. Если Дзен заметит, что у вас появились новые интересы, он начнёт учитывать их при составлении ленты.
Чтобы пользоваться браузером было комфортно, он должен быть не только красивым и удобным, но и ещё и быстрым и безопасным. За последнее в Яндекс.Браузере отвечает - комплекс технологий, которые берегут пароли, блокируют мошеннические сайты, позволяют без приключений подключаться к публичным сетям Wi-Fi и оплачивать услуги в интернете. Со скоростью помогает режим . Он автоматически включается при медленном соединении и ускоряет загрузку страниц. Это происходит за счёт уменьшения объёма данных: «тяжёлое» содержимое страницы - обычно это видео и картинки - сжимается на серверах Яндекса и только после этого передаётся пользователю. В результате экономится не только время, но и трафик.
Если вам интересно следить за тем, как развивается Яндекс.Браузер, вы можете установить его
и участвовать в тестировании новых возможностей Браузера.
Интернет сегодня - это кладезь информации планетарных масштабов, где каждый житель Земли способен найти практически всё, что ему требуется. Обладая немыслимыми объёмами данных и сведений, человечество также имеет все необходимые средства для максимально быстрого и комфортного поиска того, что требуется каждому в определённый момент времени. Этими средствами являются поисковые системы, которыми каждый из нас пользуется ежедневно: Google, Yandex, Rambler, Yahoo и многие другие технологии со своими уникальными возможностями под разные предпочтения.
И объединяет их ровным счётом одно простое свойство - ни одна из систем не является неким сверхтехнологичным центром, хранящим в своих ресурсах невообразимое количество информации на все случаи жизни. Все они по своей сути являются путеводителями для пользователей по огромным просторам Интернета и работают по определённым программным алгоритмам.
поисковой машины «Яндекс»: базовые основы
Функционал «Яндекса» позволяет довольно гибко сортировать все получаемые результаты с учётом конкретных доменов, регионов, языков и многих других параметров. Формат вводимых данных и получаемые результаты могут настраиваться и фильтроваться пользователями при помощи простых комбинаций символов. Благодаря этому существенно повышаются эффективность и удобство поиска.
Каждый запрос от пользователя сначала отправляется на наиболее свободный сервер (сразу после автоматического анализа на загруженность системы), после чего его обработкой занимается программа «Метапоиск». Софт в реальном времени проводит анализ введённой информации в поисковой строке на предмет лингвистики, географического положения пользователя, принадлежности запроса к категориям «наиболее популярных»/«недавно заданных» и т. д. Результаты поиска для этих случаев на некоторое время сохраняются в кэше «Метапоиска», благодаря чему выдача необходимой информации осуществляется быстрее.
В случае поиска более редкой информации, сведения о которой в кэше отсутствуют, обработка запроса перенаправляется к другому программному механизму - «Базовый поиск». Тот анализирует всю базу данных, разбитую по различным дублирующимся серверам для ускорения процессов поиска, и выдаёт найденную информацию обратно «Метапоиску».
Все полученные данные в итоге упорядочиваются и предъявляются пользователю в готовом, удобно воспринимаемом виде. Весь процесс в среднем занимает максимум 1-2 секунды.
Правильный поиск в «Яндекс»: язык поисковых запросов и особенности синтаксиса
Наличие определённых слов в полученных результатах, а также их взаимное расположение можно легко настраивать при помощи специальных операторов, формирующих язык поисковых запросов «Яндекса».
| Оператор | Функция | Пример использования |
| + | Отображение результатов по тем ресурсам, в которых обязательно есть обозначенное оператором слово. Язык запросов поисковой системы «Яндекс» допускает многократное использование при наличии двух или более слов в запросе. | всемирная+паутина+интернет «Яндекс» выдаст те результаты, которые точно содержат слова «паутина», «интернет» и, возможно, «всемирная». |
| " | Поиск по конкретно заданной форме или последовательности символов. | "уходит далеко в багровый закат" Результаты поиска обязательно будут содержать в себе данную фразу без изменений. |
| * | Используется только лишь с предыдущим оператором. Данный символ позволяет организовать поиск цитаты с пропущенными словами. | уходит *в багровый закат Поисковик выдаст результаты с данной цитатой и пропущенным словом. уходит ** закат Поисковик выдаст результаты с данной цитатой и пропущенными словами. |
| & | Поиск результатов с предложениями, которые содержат объединённые данным оператором слова. | красиво & интерьер & дом Пользователю будут представлены результаты, в которых как минимум одно предложение содержит данный набор слов (их можно задавать оператором от двух и более). |
| && | Поиск ресурсов, которые просто содержат данный набор слов. | референдум && Великобритания && Европа & кризис Будут выданы все результаты, содержащие эти слова вне зависимости от расстояния и расположения друг к другу. |
По признакам служебной информации
Существуют операторы поисковых запросов «Яндекс» для уточнения сведений по таким параметрам, как: заголовки, типы файлов, хост, домены, дата последнего изменения страниц результатов и их язык.
| Оператор | Функция | Пример использования |
| title: | Поиск по документам, содержащим слова из запроса в заголовках. | title: машиностроение Будут найдены документы со словом «машиностроение» и его словоформами в заголовке. title: (машиностроение ФРГ) Будут найдены документы с заголовками, содержащие слова «машиностроение» и «ФРГ» (для запросов, в которых нужно скомбинировать для поиска два и более слова, необходимо ставить скобки). |
| mime: | Поиск по документам определённого формата. | шаблон резюме mime:docx Результатами поиска будут все документы формата.docx, которые содержат слова «шаблон» и «резюме». |
| host: | Поиск по страницам, которые размещены на определённом хосте. | законопроект host:www.yandex.ru На хосте www.yandex.ru будет проведён поиск по всем документам, содержащим слово «законопроект». |
| domain: | Поиск по страницам всего домена. | хилари клинтон host:www.whitehouse.gov На домене www.whitehouse.gov будет проведён поиск всех документов, содержащих слова «хилари» и «клинтон». |
| date: | Поиск по страницам с учётом даты их последнего изменения (использование языка запросов «Яндекс» предусматривает также отсутствие значения дня и месяца, если их заменить символом *). | событие дня date:20160624 Будут найдены все документы, содержащие слова «событие» и «дня», а также их словоформы, дата последних изменений которых соответствует 24.06.2016 саммит date:20150819..date20150909 Поиск результатов, дата последних изменений которых находится в интервале от 19.08.2015 до 09.09.2015 круиз date:>20160611 Отображаются все результаты, дата последних изменений которых позднее 11.06.2016
|
| lang: | Поиск по страницам на конкретно указанном языке:
| green card lang:en Поиск англоязычных документов по данному запросу. |
Практически любой зарубежный аналог имеет подобный язык запросов. Язык поисковых запросов «Яндекса», в свою очередь, от конкурентов по большому счёту отличается чуть более расширенными возможностями и функциями.
Морфологические уточнения
По умолчанию поисковик предлагает пользователю широкий спектр выдаваемых результатов по введённому запросу, основу чего составляет не только само введённое слово/фраза, но и различные его формы (падеж, род, склонение, число и т. д.). Также учитываются вариации части речи (будь то существительное, глагол, прилагательное и т. д.) и регистр первой буквы. К примеру, при вводе в поисковую строку «атаковал» пользователь получит информацию и по прочим глагольным формам: «атаковать», «атакую», «атакован» (но однокоренные слова наподобие «атака», «атакованный», учитываться не будут). При этом будут показаны результаты как с заглавной первой буквой в запрошенном слове, так и с маленькой.

Практически все особенности языка запросов различных поисковых систем основаны на подобных принципах работы. В «Яндексе» ограничение по морфологическим признакам может пригодиться для более точной работы поисковика:
| Оператор | Функция | Пример использования |
| ! | Поиск слова исключительно в заданной форме. Язык поисковых запросов «Яндекса» допускает многократное использование оператора при наличии двух или более слов в запросе. | !интернет «Яндекс» выдаст все результаты в заданной форме запроса с заглавной и строчной первой буквой. !Интернет «Яндекс» выдаёт результаты по заданной форме запроса, начинающиеся исключительно с заглавной буквы. |
| !! | Чуть более широкий поиск слова и производных его форм. | !!пень Будут выданы результаты любой из форм этого слова («пнём», «пну», «пеньком» и т. д.), однако результаты со схожей словоформой глагола «пинать» будут исключены. |
Специальные методы подбора ключевых слов под контекстную рекламу
Языки поисковых запросов также распространяются далеко за пределы пользовательского сегмента, награждая простыми рабочими инструментами и рекламодателей. В частности, для подобных целей «Яндекс» имеет на вооружении целый ряд алгоритмов и операторов, позволяющих эффективно продвигать свои сайты и услуги в поисковой системе.
Логика показа контекстной рекламы на запросы пользователя основана на подборе слов, тематически относящихся к предмету этого объявления, а также на иных их словоформах. Например, подобные методы позволяют показывать объявление о юридических услугах не только лишь в ответ на «юридические услуги в городе N», а ещё и тем пользователям, которые делали схожие запросы (будь то «адвокаты город N цены», «адвокатские конторы», «юрист город N дёшево» и т. п.). В результате реклама будет отображаться более широкой аудитории пользователей, и это, соответственно, потенциально привлечёт больше внимания к ней.

Однако объявления должны быть показаны лишь тем пользователям, которые делают тематически смежные запросы в поисковике. К примеру, реклама юридических курсов никак не будет эффективной, если она будет показана пользователям, нуждающимся в услугах адвоката на данный момент. Регулирование подобных моментов осуществляется с помощью целого перечня операторов в поисковой системе «Яндекс». Описание языка запросов для рекламных задач в целом будет выглядеть так, как показано ниже.
| Оператор | Функция | Пример использования |
| - | Исключение для слов в запросах, когда объявление показываться не будет. Допускается многократное использование оператора при необходимости задать два или больше исключений. | юрист-курсы-дёшево Объявление будет показываться по всем запросам со словами «юрист» и «дёшево», но исключая те, которые содержат в себе слово «курсы». юрист-курсы-практика |
| + | Отображение рекламы для тех запросов, в которых есть определённое слово/слова. | +аренда +квартиры+Сочи недорого |
| ! | Оператор служит определением конкретной формы слова в запросах, согласно которой сообщение будет показываться (либо наоборот). | !клуб!Лепассо Реклама показывается только для тех запросов, в которых содержится хотя бы одно из этих двух слов в конкретно заданной форме. При этом «Лепассо» в запросе обязательно должно начинаться с заглавной буквы для отображения объявления. !клуб!Лепассо-!пейнтбол |
| Группировка слов для сложных запросов, состоящих из нескольких слов (язык поисковых запросов «Яндекса» позволяет использовать эту функцию для двух или более слов). | машина-(аренда напрокат) Объявление будет показываться при запросе, содержащих слово «машина», но в то же время не имеющие слова «аренда» и «напрокат». +(машина купить Владивосток) дёшево |
|
| "" | Показ объявления для запросов, содержащих только слова в кавычках или их словоформы. | "программист" Реклама показывается для запросов этого слова и его словоформ наподобие «программиста», «программисту». В то же время объявление не будет показано для таких запросов пользователей, как «программист ремонт компьютера недорого», «программист взлом сайта». |
Уроки комфорта и простоты от поисковых подсказок «Яндекса»
Упрощение процесса ввода поисковой информации при помощи подсказок воспринимается уже без какого-либо ажиотажного восторга. Такая технология сегодня есть в каждой популярной поисковой системе, основывается она на предварительной выдаче популярных запросов, схожих с введёнными пользователем в поисковую строку буквами.
«Яндекс» эту систему реализует посредством некоторых фирменных особенностей. Все наборы подсказок обрабатываются и группируются из числа наиболее массовых запросов пользователей. Используются также и научные термины из энциклопедических статей, названия фильмов, музыкальных произведений и иного тематически подходящего контента. В итоге пользователь с момента ввода самой первой буквы в поисковую строку получает под нею целый перечень вариантов наиболее популярных запросов, начинающихся с тех же символов.

К тому же в подсказках могут сразу указываться ссылки на нужные сайты или же ответ на заданный вопрос. К примеру, достаточно ввести половину запроса «длина окружности», как в соответствующем поле под поисковой строкой пользователю будет представлена готовая формула расчёта. Спрашивая «столица Австралии», вы не успеете дописать фразу до конца, как «Яндекс» тут же выдаст эти сведения в перечне подсказок.
Если же ссылка на какой-либо сайт будет релевантным ответом на запрос, то этот адрес будет доступен сразу в том же поле. Такой подход позволит быстрее перейти на нужный ресурс, минуя список всех найденных результатов.
Фильтрация непотребного контента
Функционал «Яндекса» также предусматривает исключение ресурсов «18+» из поисковых результатов вне зависимости от используемых средств языка запросов. Полезна эта функция будет в первую очередь для защиты малолетних пользователей от «материалов для взрослых» в Сети. И даже если ребёнок не стесняется использовать в действии все средства, которыми богат язык поисковых запросов «Яндекса», то это всё равно ему никак не поможет преодолеть барьер от подобных сайтов.

В поиске «Яндекса» для пользователей предусмотрено 3 режима :
- «Без защиты» - какие-либо ограничения на выдаваемые результаты полностью отсутствуют.
- «Умеренный» - если запрос пользователя явно не направлен на поиск сайтов «18+», то они в таком случае изымаются из результатов поиска.
- «Семейный» - нецензурный контент полностью отсутствует в результатах поиска.
Все эти варианты защиты от недетского содержимого контролируются в соответствующем меню настроек «Яндекса».
Дополнительные функции поисковой машины
Помимо широкого спектра различных операторов языка запросов, «Яндекс» также предлагает ещё пару способов поиска информации:
- «Расширенный» - более приятный сервис с интуитивно понятной структурой для тех, кто нуждается в использовании средств языка запросов. Достаточно только ввести в соответствующие поля необходимые параметры (поиск по конкретному ресурсу, регион, точность совпадения со словами поискового запроса, поиск по заголовкам, язык, формат документа, дата последнего обновления и т. д.), не прибегая к менее комфортному ручному вводу операторов. «Расширенный поиск» и язык запросов «Яндекса» - один и тот же функционал, но с разницей в том, что первый предлагает использование тех же операторов в более удобной форме.

- «Дзен-поиск». Основываясь на истории поисковых запросов пользователя, «Яндекс» предлагает последнему сервис публикаций в СМИ. Доступен только для мобильных устройств и внешне представляет собою набор из превью новостей, подобранных согласно истории просмотров. Пользователь может выбрать любую понравившуюся публикацию, прочитать несколько первых абзацев и, если она ему интересна, перейти на сайт издателя по этому материалу. В противном случае достаточно выбрать "Не нравится" для того, чтобы не отображать конкретную новость или отметить таким образом весь ресурс, исключая его из своей новостной ленты.
Механизмы защиты от нежелательной и вредоносной информации
Основным свойством любой поисковой машины являются не только лишь разнообразные операторы поисковых запросов. «Яндексу» также характерен высокий уровень безопасности всех найденных результатов. Базовая проверка страниц и предупреждения о вредоносных сайтах у этой поисковой системы появились в 2009 году. Обнаружение угроз осуществляется двумя технологиями:
- Антивирусная защита, приобретённая у компании Sophos и основанная на сигнатурном подходе: обращение антивирусной системы при заходе пользователя на веб-страницу к базе данных, содержащей информацию об известном вредоносном ПО. Невзирая на высокую скорость работы, подобная технология практически полностью бесполезна в случае столкновения с новыми вирусными угрозами. Поэтому «Яндекс» дополнительно использует и вторую технологию.
- Фирменный антивирусный комплекс, основу которого составляет Сначала защита при обращении к сайту анализирует, делает ли он запрос у браузера дополнительных файлов, перенаправляет ли на посторонний ресурс и т. д. Если обнаруживаются посторонние действия ресурса без ведома пользователя (запуск модулей JavaScript, полноценных программ, каскадных таблиц стилей), то он заносится в чёрный список опасных сайтов и базу вирусных сигнатур. Владелец самого сайта также будет уведомлён об этих угрозах, и все последующие проверки будут периодически проводиться вплоть до того момента, как все проблемы безопасности на нём не будут полностью устранены.

Подобный подход к анализу предоставляемых страниц с результатами поиска в сочетании с фирменными технологиями «Яндекса» позволили минимизировать процент заражённых сайтов в этом поисковике до единиц. Ежедневные проверки «Яндекса» охватывают в общей сложности до 23 миллионов ресурсов, а за месяц это число доходит примерно до 1 миллиарда.
Добрый день, уважаемые читатели моего сео блога . Эта статья о том, как работает поисковая система Яндекс , какие она использует технологии и алгоритмы для ранжирования сайтов, что делает для подготовки ответа пользователям. Многие знают, что этот флагман русского поиска задает тон в Рунете, владеет самой большой базой данных в Евразии, оперирует контентом более чем миллиарда страниц, знает ответ на любой вопрос. По данным Liveinternet за август 2012 года, доля Яндекса в России составляет 60,5%. Месячная аудитория портала - 48,9 миллионов человек. Но самое главное, для нас, блоггеров в том, как поисковая система получает наши запросы, как их обрабатывает и какой результат получается на выходе. С одной стороны, зная и понимая эту информацию, нам проще пользоваться всеми ресурсами Яндекса, с другой стороны — легче продвигать наши блоги. Поэтому, предлагаю вместе со мной посмотреть самые важные технологии лучшей поисковой системы Рунета.
Когда пользователь Интернета впервые хочет обратиться за информацией к поисковой системе, у него может возникнуть один вопрос: «Как происходит поиск?» Но когда он ее получает, зачастую этот вопрос меняется на другой: «Почему так быстро?» И действительно, почему поиск какого-нибудь файла на компьютере занимает 20 секунд, а результат запроса со всей сети компьютеров по всему миру появляется через секунду? Самое интересное, что первых два вопроса (как происходит поиск и почему 1 секунда) могут быть в одном ответе — поисковая система заранее подготовилась к запросу пользователя.
Чтобы понять принцип работы Яндекса, как и другой поисковой системы, проведем аналогию с телефонным справочником. Чтобы найти любой номер телефона, необходимо знать фамилию абонента и любой поиск занимает в таком случае максимум минуту, потому что все страницы справочника — это сплошной алфавитный указатель. А вот представьте себе, если бы поиск шел по другому варианту, где номера телефонов были бы упорядочены по самим номерам. После таких поисков, которые уже затянутся на более продолжительное время, цифры перед глазами искавшего будут еще очень долго стоять. 🙂
Так и поисковая система раскладывает всю информацию из Интернета в удобном для нее виде. И самое главное, все эти данные заранее кладутся в ее справочник, до прихода посетителя со своими запросами. То есть, когда мы задаем Яндексу вопрос, он уже знает наш ответ. И выдает нам его через секунду. Но эта секунда включает в себя ряд важнейших процессов, которые мы сейчас подробно рассмотрим.
Индексирование Интернета
Яндекс ру собирает в сети Интернет всю информацию, до которой может дотянутся. С помощью специального оборудования, отсматривается весь контент, в том числе и изображения по визуальным параметрам. Занимается таким сбором поисковая машина, а сам процесс сбора и подготовки данных называется индексированием. В основу такой машины входит компьютерная система, которая по другому именуется поисковый робот. Он регулярно обходит проиндексированные сайты, проверяет их на наличие нового контента, а также сканирует Интернет в поисках удаленных страниц. Если он обнаруживает, что какая-то такая страница больше не существует или закрыта от индексирования, то удаляет ее из поиска.
Как поисковый робот находит новые сайты? Во-первых, благодаря ссылкам с других сайтов. Потому что если на новый веб-ресурс поставлена ссылка с уже проиндексированного сайта, то при следующем посещении второго, робот зайдет в гости и к первому. Во-вторых, в есть чудесный сервис, в народе называемый «аддурилка» (от словосочетания на английском языке -addurl — добавить адрес). В нем можно внести адрес Вашего нового сайта, который через некоторое время посетит поисковый робот. В-третьих, с помощью специальной программы «Яндекс.Бар» отслеживается посещение пользователей, которые ею пользуются. Соответственно, если человек попал на новый веб-ресурс, в скором времени там появится и робот.
Все ли страницы попадают в поиск? Каждый день индексируются миллионы страниц. Среди них есть страницы различного качества, в которых может содержатся разная информация — от уникального контента до сплошного мусора. Причем, как говорит статистика, мусора в Интернете намного больше. Каждый документ поисковый робот анализирует с помощью специальных алгоритмов. Он определяет, есть ли у него какая-нибудь полезная информация, сможет ли он ответить на запрос пользователя. Если нет, то такие страницы не берут «в космонавты», если же да, то он включается в поиск.
После того, как робот посетил страницу и определил ее полезность, она появляется в хранилище поисковой машины. Здесь идет разбор любого документа до самых основ, как говорят мастера автоцентра — до винтиков. Страница очищается от html-разметки, чистый текст проходит полную инвентаризацию — подсчитывается местоположение каждого слова. В таком разобранном виде страница превращается в таблицу с цифрами и буквами, которую по другому называют индексом. Теперь, чтобы не случилось с веб-ресурсом, в котором содержится эта страница, ее последняя копия всегда есть в поиске. Даже если сайт уже не существует, слепки его документов еще некоторое время хранятся в Интернете.
Каждый индекс вместе с данными о типах документов, кодировке, языке вместе с копиями составляют поисковую базу . Она периодически обновляется, поэтому находится на специальных серверах, с помощью которых происходит обработка запросов пользователей поисковой системы.
Как часто происходит процесс индексации? В первую очередь это зависит от типов сайтов. Веб-ресурс первого типа очень часто меняет содержимое своих страниц. То есть, когда к этим страницам каждый раз приходит поисковый робот, они каждый раз содержат другой контент. По ним ничего в следующий раз уже не получится найти, поэтому такие сайты не включаются в индекс. Второй тип сайтов — хранилища данных, на страницах которых периодически добавляются ссылки на документы для скачивания. Контент такого сайта обычно не меняется, поэтому его робот посещает крайне редко. Другие сайты зависят от частоты обновления материала. Имеется в виду следующее — чем быстрее появляется новый контент на сайте, тем чаще приходит поисковый робот. И приоритет отдается в первую очередь наиболее важным веб-ресурсам (новостной сайт на порядок важнее, чем любой блог, к примеру).
Индексирование позволяет выполнить первую функцию поисковой системы — сбор информации на новых страницах в сети Интернет. Но у Яндекса есть и вторая функция — поиск ответа на запрос пользователя в уже подготовленной поисковой базе.
Яндекс готовит ответ
Процессом обработки запроса и выдачей релевантных ответов занимается компьютерная система «Метапоиск» . Для своей работы сначала она собирает всю вводную информацию: из какого региона был осуществлен запрос, к какому классу относится, есть ли ошибки в запросе и т.д. После такой обработки метапоиск проверяет, есть ли в базе точно такие же запросы с такими же параметрами. Если ответ положительный, то система показывает пользователю заранее сохраненные результаты. Если же такого вопроса в базе не существует, метапоиск обращается поисковой базе, в которой содержатся данные индекса.
И вот здесь происходят удивительные вещи. Представьте себе, что существует один супермощный компьютер, который хранит в себе весь обработанный поисковыми роботами Интернет. Пользователь задает запрос и в ячейках памяти начинается поиск всех документов, причастных к запросу. Ответ найден и все довольны. Но возьмем другой случай, когда появляется очень много запросов, содержащих в своем теле одинаковые слова. Система должна каждый раз пройтись по одним и тем же ячейкам памяти, что может увеличить время на обработку данных в разы. Соответственно, увеличивается время, что может привести к потери пользователя — он обратится за помощью к другой поисковой системе.
Чтобы таких задержек не было, все копии в индексе сайтов распределены по разным компьютерам. После передачи запроса, метапоиск дает команду таким серверам искать свой кусочек с текстом. После чего, все данные от этих машин возвращаются в центральный компьютер, он объединяет все полученные результаты и выдает пользователю первую десятку самых лучших ответов. С такой технологией сразу убивается два зайца: в несколько раз уменьшается время поиска (ответ получается за доли секунды) и благодаря увеличению площадок дублируется информация (данные не теряются из-за внезапных поломок). Сами компьютеры с дублирующей информацией составляют дата-центр — это комната с серверами.

Когда пользователь поисковой системы задает свой запрос,в 20-ти случаях из 100 получаются неоднозначные цели в вопросе. Например, если он пишет в строке поиска слово «Наполеон», то еще не известно, какой ответ ожидает — рецепт торта или биография великого полководца. Или фраза «Братья Гримм» — сказки, фильмы, музыкальная группа. Чтобы такой возможный веер целей сузить до конкретных ответов в Яндексе существует специальная технология С п е к т р . Она учитывает потребности пользователей, используя статистику поисковых запросов. Из всех вопросов, заданных в Яндексе посетителями, Спектр выделяет в них различные объекты (имена людей, названия книг, модели машин и т.д.) Эти объекты распределены по некоторым категориям. На сегодняшний момент таких категорий насчитывается более 60-ти. С помощью них поисковая система имеет в своей базе разные значения слов в запросах пользователей. Интересно, что эти категории периодически проверяются (анализ происходит пару раз в неделю), что позволяет Яндексу более точно давать ответы на поставленные вопросы.
На базе технологии Спектр Яндекс организовал диалоговые подсказки. Они появляются под поисковой строкой, в которой пользователь набирает свой неоднозначный запрос. В этой строке отражены категории, к которым может относится объект вопроса. От выбора пользователем такой категории зависят дальнейшие результаты поиска.
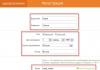
 От 15 до 30% всех пользователей поисковой системы Яндекс желают получить только местную информацию (данные того региона, в котором они живут). Например, о новых фильмах в кинотеатрах своего города. Поэтому ответ на такой запрос должен быть разным для каждого региона. В связи с этим, Яндекс использует свою технологию поиска с учетом регионов
. Например, вот такие ответы могут получить жители, которые ищут репертуар фильмов в своем кинотеатре «Октябрь»:
От 15 до 30% всех пользователей поисковой системы Яндекс желают получить только местную информацию (данные того региона, в котором они живут). Например, о новых фильмах в кинотеатрах своего города. Поэтому ответ на такой запрос должен быть разным для каждого региона. В связи с этим, Яндекс использует свою технологию поиска с учетом регионов
. Например, вот такие ответы могут получить жители, которые ищут репертуар фильмов в своем кинотеатре «Октябрь»:

А вот такой результат получат жители города Ставрополь на тот же запрос:

Регион пользователя определяется в первую очередь по его ip-адресу. Иногда эти данные не точны, потому что ряд провайдеров могут сразу работать на несколько регионов, а значит и менять ip-адреса cвоим пользователям. В принципе, если такое случилось с Вами, Вы легко можете поменять в настройках в поисковой системе свой регион. Он указан в правом верхнем углу на странице выдачи результатов. Изменить его можно .
Поисковая система Яндекс ру — результаты ответа
Когда Метапоиск подготовил ответ, поисковая система Яндекс должна выдать его на странице с результатами. Она представляет собой перечень ссылок на найденные документы с небольшой информацией по каждому. Задача технологии выдачи результатов — максимально информативно предоставить пользователю самые релевантные ответы. Шаблон одной такой ссылки выглядит следующим образом:

Рассмотрим эту форму результата поподробней. Для заголовка результата поиска Яндекс часто использует название заголовка страницы (то, что оптимизаторы прописывают в теге title). Если же его нет, то здесь появляются слова из названия статьи или поста. Если текст заголовка большой, поисковая система ставит в это поле его фрагмент, который больше всего релевантен к заданному запросу.
Очень редко, но бывает так, что заголовок не соответствует содержанию запроса. В таком случае Яндекс формирует свой заголовок результата поиска, используя текст в статье или посте. Он обязательно будет иметь слова запроса.
Для сниппета поисковая система использует весь текст на странице. Она выбирает все фрагменты, где присутствует ответ на запрос, а потом выбирает самый релевантный из них и вставляет в поле формы ссылки на документ. Благодаря такому подходу, грамотный оптимизатор может после увиденного сниппета его переделать, тем самым улучшив привлекательность ссылки.
Для лучшего восприятия результата на запрос пользователя, заголовки оформляются как ссылки в тексте (выделение синим цветом с подчеркиванием). Для привлекательности веб-ресурса и его узнаваемости добавляется фавикон — маленький фирменный значок сайта. Он появляется слева от текста в первой строке перед заголовком. Все слова, которые входили в запрос в ответе тоже выделены жирным шрифтом для удобства восприятия.
В последнее время в сниппет поисковая система Яндекса добавляет различную информацию, которая поможет пользователю еще быстрее и точнее найти свой ответ. К примеру, если пользователь в своем запросе пишет название какой-либо организации, то в сниппете Яндекс добавит адрес ее, контактные телефоны и ссылку на месторасположение в географических картах. Если поисковой системе знакома структура сайта, в котором есть документ с ответом для пользователя, он ее обязательно покажет. Плюс к этому Яндекс тут же может добавить в сниппет наиболее посещаемые страницы такого веб-ресурса, чтобы при желании посетитель смог сразу перейти в нужный ему раздел, экономя свое время.
Есть сниппеты, которые содержат в себе цену какого-либо товара для интернет-магазина, рейтинг отеля или ресторана в виде звездочек, другая интересная информация с различными цифрами о объектах в документах поиска. Задача такой информации — дать полный перечень данных о тех предметах или объектах, которые интересны пользователю.
В целом уже с различными примерами страница с ответами будет выглядеть так:

Ранжирование и асессоры
В задачу Яндекса входит не только поиск всех возможных вариантов ответа, но и подбор самых лучших (релевантных). Ведь пользователь не будет рыться во всех ссылках, которые ему предоставит в качестве результата поисков Яндекс. Процесс упорядочивания результатов поиска называется ранжированием . То есть именно ранжирование определяет качество предлагаемых ответов.
Есть правила, по которым Яндекс определяет релевантные страницы:
- понижение в позициях на странице с результатами ждут сайты, которые ухудшают качество поиска. Обычно это такие веб-ресурсы, владельцы которых пытаются обмануть поисковую систему. К примеру, это сайты со страницами, на которых находится бессмысленный или невидимый текст. Конечно, он видим и понятен поисковому роботу, но не посетителю, читающему этот документ. Или сайты, которые при переходе на ссылке в зоне выдачи сразу переводят пользователя совсем на другой сайт.
- не попадают в выдачу результатов или сильно понижаются в ранжировании сайты, содержащие в себе эротический контент. Это связано с тем, что часто такие веб-ресурсы используют агрессивные методы продвижения.
- зараженные вирусами сайты не понижаются в выдаче и не исключаются с результатов поиска — в этом случае пользователь информируется об опасности с помощью специального значка. Это связано с тем, что Яндекс предполагает, что на таких веб-ресурсах могут находиться важные документы по запросу посетителя поисковой системы.
К примеру, так будет ранжировать Яндекс сайты по запросу «яблоко»:

Кроме факторов ранжирования Яндекс использует специальные образцы с запросами и ответами на них, которые пользователи поисковой системы считают самыми подходящими. Такие образцы ни одна машина не сможет сделать на данный момент — это прерогатива человека. В Яндексе такие специалисты называются асессорами . В их задачу входит полный анализ всех документов поиска и оценка ответов на заданные запросы. Они выбирают лучшие ответы и составляют специальную обучающую выборку. В ней поисковая машина видит зависимость между релевантными страницами и их свойствами. Имея такую информацию Яндекс может подобрать для каждого запроса оптимальную формулу ранжирования. Метод построения такой формулы называется Матрикснет. Плюс этой системы в том, что она устойчива к переобучению, что позволяет учитывать большое количество факторов ранжирования, не увеличивая количество ненужных оценок и закономерностей.
В завершении моего поста хочу показать вам интересную статистику, собранную поисковой системой Яндекса в процессе своей работы.
1. Популярность личных имён в России и российских городах (данные взяты из учетных записей блоггеров и пользователей социальных сетей в марте 2012 года).


В 1863 году великий писатель Жюль Верн создал очередную свою книгу «Париж в ХХ веке». В ней он подробно описал метро, автомобиль, электрический стул, компьютер и даже сеть Интернет. Однако издатель отказался печатать книгу и она пролежала более 120 лет, пока ее не нашел правнук Жюля Верна в 1989 году. Издана была книга в 1994году.
Поисковые системы Google, Yahoo, Яндекс, Rambler, Nigma, Aport... служат для обнаружения необходимого ресурса в сети Интернет по ключевым словам. Эти системы, или, как их иначе называют, поисковые машины, ежедневно перебирают миллионы WWW серверов, индексируют и каталогизируют найденные ресурсы. Возможность поиска ресурса в Интернет очень удобна, но нельзя забывать о том, что Сеть живет своей жизнью - каждый день появляются тысячи новых страниц, некоторые старые исчезают... Поэтому, поисковые системы не всегда выдают самую точную информацию.
Средства поиска и структурирования, иногда называемые поисковыми механизмами, используются для того, чтобы помочь людям найти информацию, в которой они нуждаются. Средства поиска типа агентов, пауков, кроулеров и роботов используются для сбора информации о документах, находящихся в Сети Интернет. Это специальные программы, которые занимаются поиском страниц в Сети, извлекают гипертекстовые ссылки на этих страницах и автоматически индексируют информацию, которую они находят для построения базы данных. Каждый поисковый механизм имеет собственный набор правил, определяющих, как cобирать документы. Некоторые следуют за каждой ссылкой на каждой найденной странице и затем, в свою очередь, исследуют каждую ссылку на каждой из новых страниц, и так далее. Некоторые игнорируют ссылки, которые ведут к графическим и звуковым файлам, файлам мультипликации; другие игнорируют cсылки к ресурсам типа баз данных WAIS; другие проинструктированы, что нужно просматривать прежде всего наиболее популярные страницы.
Поисковые системы -- веб-сайт, предоставляющий возможность поиска информации в Интернете. Большинство поисковых систем ищут информацию на сайтах Всемирной паутины, но существуют также системы, способные искать файлы на ftp-серверах, товары в интернет-магазинах, а также информацию в группах новостей Usenet.
Как правило, основной частью поисковой системы является поисковые машины-- комплекс программ, обеспечивающий функциональность поисковой системы. Основными критериями качества работы поисковой машины являются релевантность (степень соответствия запроса и найденного, то есть уместность результата), полнота базы, учёт морфологии языка. Индексация информации осуществляется специальными поисковыми роботами. В последнее время появился новый тип поисковых движков, основанных на технологии RSS, а также среди XML-данных разного типа.
Улучшение поиска -- это одна из приоритетных задач сегодняшнего Интернета (см. про основные проблемы в работе поисковых систем в статье Глубокая паутина).
По данным компании Net Applications в декабре 2007 года использование поисковых систем на Западе распределялось следующим образом (приложение 2, рисунок 2):
Google -- 77,04 %, Yahoo -- 12,46 %, MSN -- 3,33 %, Microsoft Live Search -- 2,57 %, AOL -- 2,12 %, Ask -- 1,38 %, AltaVista -- 0,13 %, Excite -- 0,07 %, Lycos -- 0,02 %, All the Web -- 0,02 %.
В вышеприведенный отчёт не входят российские поисковики, такие как, например, Яндекс, Рамблер или Nigma.
Одним из первых инструментов поиска в интернете (до WWW) был Archie. Первой поисковой системой для Всемирной паутины был «Wandex», уже не существующий индекс, который создавал «World Wide Web Wanderer» -- бот, разработанный Мэтью Грэем (англ. Matthew Gray) из Массачусетского технологического института в 1993. Также в 1993 году появилась поисковая система «Aliweb», работающая до сих пор. Первой полнотекстовой (т. н. «crawler-based», то есть индексирующей ресурсы при помощи робота) поисковой системой стала «WebCrawler», запущенная в 1994. В отличие от своих предшественников, она позволяла пользователям искать по любым ключевым словам на любой веб-странице -- с тех пор это стало стандартом во всех основных поисковых системах. Кроме того, это был первый поисковик, о котором было известно в широких кругах. В 1994 был запущен «Lycos», разработанный в университете Карнеги Мелона.
Вскоре появилось множество других конкурирующих поисковых машин, таких как «Excite», «Infoseek», «Inktomi», «Northern Light» и «AltaVista». В некотором смысле они конкурировали с популярными интернет-каталогами, такими, как «Yahoo!». Позже каталоги соединились или добавили к себе поисковые машины, чтобы увеличить функциональность. В 1996 году русскоязычным пользователям интернета стало доступно морфологическое расширение к поисковой машине Altavista и оригинальные российские поисковые машины Rambler и Aport. 23 сентября 1997 была открыта поисковая машина Яндекс.
В последнее время завоёвывает всё большую популярность практика применения методов кластерного анализа и метапоиска. Из международных машин такого плана наибольшую известность получила «Clusty» компании Vivisimo. В 2005 году на российских просторах при поддержке МГУ запущен поисковик Nigma, поддерживающий автоматическую кластеризацию. В 2006 году открылась российская метамашина Quintura, предлагающая визуальную кластеризацию в виде облака ключевых слов. Nigma тоже экспериментировала с визуальной кластеризацией.
Помимо поисковых машин для Всемирной паутины, существовали и поисковики для других протоколов, такие как Archie для поиска по анонимным FTP-серверам и «Veronica» для поиска в Gopher.
Популярные поисковые системы
Всеязычные: Google (34,4 % Русскоязычного сегмента); Bing (0,9 % Русскоязычного сегмента); Yahoo! (0,2 % Рунета) и принадлежащие этой компании поисковые машины: Inktomi, AltaVista, Alltheweb.
Англоязычные и международные: AskJeeves (механизм Teoma).
Русскоязычные -- большинство «русскоязычных» поисковых систем индексируют и ищут тексты на многих языках -- украинском, белорусском, английском и др. Отличаются же они от «всеязычных» систем, индексирующих все документы подряд, тем, что в основном индексируют ресурсы, расположенные в доменных зонах, где доминирует русский язык или другими способами ограничивают своих роботов русскоязычными сайтами. Яндекс (46,3 % Рунета), Mail.ru (8,9 % Рунета), Rambler (3,3 % Рунета), Nigma (0,5 % Рунета), Генон (0,1 % Рунета), Gogo.ru (<0,1 % Рунета), Aport (<0,1 % Рунета). Мета (приложение 2, рисунок 3).
Из перечисленных поисковых систем не все имеют собственный поисковый алгоритм -- так Mail.ru и QIP.ru используют поисковый механизм Яндекса, а Nigma сочетает в себе как свой алгоритм, так и сборную выдачу от других поисковиков.
Главный плюс любой поисковой машины кроется в механизме ее работы. В отличие от каталогов, поисковики, для добавления сайтов в свою базу данных, используют специального робота-паука, который вполне удачно просматривает и индексирует все общедоступные сайты своей Глобальной Паутины. Но для удачного поиска нам будет мало лишь огромной базы нашего спутника, ведь среди всех этих терабайт информации нам нужно найти именно нужную нам.
Важнейшим фактором и залогом нашего успеха является правильность поискового запроса.
Исключение из поиска
Поисковую машину можно не только «заставлять» искать нужный текст, но и исключать некоторые слова из запроса. Если вы не хотите, что бы при поиске реферата на тему История Древнего Египта вам были предложены документы с его Культурой, просто введите в поисковое поле Google: история древнего египта -культура. В Яндексе вместо знака «-» используется сочетание знаков «~~». При таком запросе, слово «культура» было полностью исключено из критериев поиска.
Поиск с учетом регистра
Поисковые системы не учитывают регистр, все заглавные символы воспринимаются машинами как строчные, за исключением использования специального операнда. Таковым является знак восклицания «!», стоящий перед словом. Эта функция очень полезна для поиска сел или городов с распространенными названиями, к примеру «село!Кошки». В данном случае, поисковик не будет искать сайты, где речь ведется о селе, где живут кошки, а будет вести поиск с учетом заглавной буквы.