Как временно удалить свои страницы из результатов поиска Google
Этот инструмент позволяет временно блокировать страницы вашего сайта в результатах поиска Google. О том, как удалить из Google Поиска страницы, которые вам не принадлежат, читайте .
Важные примечания
Как временно исключить страницу из результатов поиска Google
- URL должен относиться к принадлежащему вам ресурсу в Search Console. Если это не так, вам нужно следовать другим инструкциям .
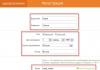
- Перейдите к инструменту удаления URL .
- Нажмите Временно скрыть .
- Укажите относительный путь
к нужному изображению, странице или каталогу. При этом учитывайте следующие требования:
- Регистр символов в URL имеет значение. URL example.com/Stranitsa и example.com/stranitsa не одинаковы.
- Путь должен относиться к корневому каталогу вашего ресурса в Search Console.
- Варианты с префиксами http и https, а также с субдоменом www и без него означают одно и то же.
Следовательно, если говорить об example.com/stranitsa , то:
- https://example.com/stranitsa не отличается;
- http://example.com/stranitsa не отличается;
- https://www.example.com/stranitsa не отличается;
- http://www.example.com/stranitsa не отличается;
- http://m.example.com/stranitsa отличается . Субдомены m. и amp. (а также все прочие) делают URL неравнозначными.
- Чтобы скрыть целый сайт , не указывайте путь и на следующем шаге выберите вариант Очистить кеш и временно скрыть все URL, которые начинаются с… .
- Нажмите Продолжить .
- Выберите нужное действие из перечисленных ниже.
- Нажмите Отправить запрос . На его обработку может потребоваться до суток. Мы не гарантируем, что запрос будет выполнен. Проверяйте статус запроса. Если он был отклонен, нажмите Подробнее , чтобы посмотреть дополнительные сведения.
- Отправьте дополнительные запросы, указав все URL, по которым может открываться та же страница, а также варианты URL с измененным регистром, если ваш сервер их поддерживает. В частности, на одну и ту же страницу могут указывать следующие URL:
- example.com/mypage
- example.com/MyPage
- example.com/page?1234
- Если вы хотите удалить URL из результатов поиска окончательно , ознакомьтесь со следующим разделом.
Удаление навсегда
Инструмент удаления URL позволяет удалять страницы только на время . Если вы хотите удалить контент из результатов поиска Google навсегда, примите дополнительные меры:
- Удалите или измените контент сайта (изображения, страницы, каталоги) и убедитесь, что сервер возвращает код ошибки 404 (не найдено) или 410 (удалено) . Файлы, формат которых отличен от HTML (например, PDF), должны быть полностью удалены с сервера. Подробнее о кодах статуса HTTP ...
- Заблокируйте доступ к контенту , например установите пароль.
- Запретите сканирование страницы с помощью метатега noindex . Этот метод менее надежен, чем остальные.
Отмена удаления URL
Если нужно восстановить страницу в результатах поиска раньше окончания временной блокировки, откройте страницу статуса в инструменте и нажмите Включить повторно рядом с выполненным запросом на удаление URL. Обработка запроса может занять несколько дней.
Использование инструмента не по назначению
Инструмент удаления URL предназначен для срочного блокирования контента, например в тех случаях, если случайно оказались раскрыты конфиденциальные данные. Использование этого инструмента не по назначению приведет к негативным последствиям для вашего сайта.
- Не используйте инструмент для удаления ненужных элементов , например старых страниц с сообщением об ошибке 404. Если вы изменили структуру своего сайта и некоторые URL в индексе Google устарели, поисковые роботы обнаружат это и повторно просканируют их, а старые страницы постепенно будут исключены из результатов поиска. Нет необходимости запрашивать срочное обновление.
- Не используйте инструмент для удаления ошибок сканирования из аккаунта Search Console. Эта функция препятствует показу адресов в результатах поиска Google, а не в аккаунте этого сервиса. Вам не нужно вручную удалять URL. Со временем они будут исключены автоматически.
- Не используйте инструмент удаления URL при полной переделке сайта "с нуля". Если в отношении сайта действуют меры, принятые вручную, или он приобретен у прежнего владельца, рекомендуем подать запрос на повторную проверку . Сообщите при этом, какие изменения вы внесли и с какими проблемами столкнулись.
- Не используйте инструмент для "отключения" сайта после взлома. Если ваш сайт был взломан и вы хотите удалить из индекса страницы с вредоносным кодом, используйте инструмент блокировки URL для блокировки новых URL, созданных злоумышленником, например http://www.example.com/buy-cheap-cialis-skq3w598.html. Однако мы не рекомендуем блокировать все страницы сайта или те URL, которые нужно будет проиндексировать в будущем. Вместо этого удалите вредоносный код, чтобы роботы Google могли повторно просканировать ваш сайт.
- Не используйте инструмент удаления URL для индексации правильной "версии" своего сайта. На многих ресурсах один и тот же контент и файлы можно найти по разным URL. Если вы не хотите, чтобы ваш контент дублировался в результатах поиска, прочитайте . Не используйте инструмент удаления URL, чтобы заблокировать нежелательные версии URL. Это не поможет сохранить предпочитаемую версию страницы, а приведет к удалению всех версий URL (с префиксами http или https, а также с субдоменом www и без него).
Была ли эта статья полезна?
Как можно улучшить эту статью?
По поводу выгрузки проиндексированных страниц, Яндекс наконец сделал то что и нужно было.
И вот теперь мы получили очень хороший инструмент с помощью которого можно получить очень интересную информацию.
Я сегодня расскажу об этой информации и вы сможете применить это для продвижения ваших сайтов.
Переходим в Яндекс.Вебмастер, в раздел «Индексирование»
И вот перед вам такая картинка(нажимайте, чтобы увеличить):

Эти данные исключённых страниц дают нам очень много информации.
Ну начнём с Редиректа:

Обычно редирект не таит в себе каких то проблем. Это техническая составляющая работы сайта.
Это обычный дубль страницы. Я бы не сказал, что это не настолько критично. Просто Яндекс из двух страниц посчитал более релевантной именно вторую страницу.
И Яндекс даже написал свой комментарий: Страница дублирует уже представленную в поиске страницу http://сайт/?p=390. Укажите роботу предпочтительный адрес с помощью 301 редиректа или атрибута rel=»canonical».
Это можно использовать следующим образом: Иногда вылетают страницы сайта которые вы продвигаете и наоборот встают в индекс их дубли. В данном случае нужно просто прописать канонический урл на обоих этих страницах на ту которую вы продвигаете.
После этого обе эти страницы добавляете в «Переобход робота».
Это та страница в мета-тегах которой прописан канонический урл на нужную страницу.

Тут как раз всё прекрасно и это обычный процесс работы сайта.
Тут также Яндекс пишет подсказку: Страница проиндексирована по каноническому адресу http://сайт/?p=1705, который был указан в атрибуте rel=»canonical» в исходном коде. Исправьте или удалите атрибут canonical, если он указан некорректно. Робот отследит изменения автоматически.

Обычно это происходит когда вы удалили какие то страницы, а редирект не поставили. Или 404 ошибку не поставили.
Какого то вреда для продвижения сайта это не даёт.
Ну и подходит к самому интересному. Недостаточно качественная страница.
Т.е. страницы нашего сайта вылетели из индекса Яндекса потом что они недостаточно качественные.
Безусловно это важнейший сигнал вашему сайту, что у вас глобальные проблемы с этими страницами.
Но не всё так однозначно как кажется.

Зачастую это страницы пагинации, поиска или другого мусора. И эти страницы правильно исключены из индекса.
Но иногда бывает, что из индекса исключают карточки товаров Интернет-магазина. Причём исключают тысячами. И это безусловного говорит о том, что с вашими страницами карточек товаров какие то серьёзные проблемы.
Я за неделю просмотрел многие Интернет-магазины и почти у всех есть подобное. Причём вылет страниц наблюдается по десятку тысяч.
Тут могут быть такие проблемы, что мы имеем несколько одинаковых страниц где товар просто разного цвета. И Яндекс считает, что это одна страница.
В данном случае тут или делать одну страницу с выбором цвета на одной странице или же дорабатывать другие страницы.
Но конечно стоит сказать, что это ГЛОБАЛЬНАЯ помощь для всех владельцев Интернет-магазинов. Вам дали ясно понять какие страницы у вас улетели и почему.
Тут нужно работать над качеством этих страниц. Может эти страницы дублируют другие, а может и нет.
Иногда на таких страницах элементарно отсутствует текст. А на некоторых отсутствует цена и Яндекс удаляет из индекса такие страницы.
А ещё я заметил, что если на странице карточки товара стоит статус «Товар отсутствует на складе», то такая страница тоже удаляется из индекса Яндекса.
В общем то работайте.
О других интересных фишках я расскажу в понедельник на своём семинаре —
Да и ещё. Многие знают такую траблу с Яндекс.Советником:

Т.е. вы заплатили за клик с Директа, а Яндекс.Советник уводит вашего оплаченного клиента на Яндекс.Маркет.
Это на самом деле вопиющий случай.
Как я понял Яндекс ничего менять не будет.
Ну хорошо, тогда поменяю я сам.
Этот Яндекс.Советник косается в первую очередь Интернет магазинов. А Интернет магазины стоят в первую очередь на движках: Битрикс, Джумла, Вебасист.
Так вот для этих движков я пишу блокиратор советника. Т.е. при установке на вашем движке этого плагина, на вашем сайте не будет работать Яндекс.Советник.
Всем кто придёт на мои семинар я позже скину эти плагины бесплатно.
Я выбрал наиболее популярные движки на которых стоят ИМ. Для сайтов услуг это не нужно. А вот для ИМ, самое то.
Если есть вопросы, то задавайте вопросы.
Привет, друзья! Надеюсь, что вы отлично отдохнули на майские праздники: наездились на природу, наелись шашлык и нагулялись по расцветающей природе. Теперь же нужно возвращаться к активной работе =) .
Сегодня я покажу результаты одного небольшого эксперимента по удалению всех страниц сайта из поисковых систем Яндекса и Google. Его выводы помогут при выборе одного из методов для запрета индексирования всего ресурса или отдельных его частей.
Передо мной встала задача - закрыть сайт к индексированию без потери его функционала. То есть ресурс должен работать, но удалиться из индекса поисковых систем. Конечно, самый верный способ просто удалить проект с хостинга. Документы будут отдавать 404-ошибку и со временем "уйдут" из базы поисковиков. Но задача у меня была другая.
- определить, какой метод запрета индексации приоритетней для поисковых систем;
- понаблюдать в динамике за скоростью ;
- собственно, удалить проекты из баз ПС.
В эксперименте участвовало 2 сайта (всем больше года). Первый: в индексе Яндекса 3000 страниц, Google - 2090. Второй: Яндекс - 734, Google - 733. Если не удалять ресурс с хостинга, то остаются 2 популярных варианта: тег meta name="robots" и запрет в robots.txt.
Для первого сайта на каждой странице была добавлена строка:
Для второго был составлен следующий robots.txt:
User-agent: *
Disallow: /
Эксперимент стартовал 14 декабря и продолжился до 9 мая. Данные снимались примерно на даты апдейтов Яндекса.
Результаты
Ниже графики динамики количества проиндексированных страниц. Сначала сайт №1 (метод удаления тег meta name="robots").

Как видно, поисковые системы вели себя примерно по одному сценарию. Но есть и различия. В Яндексе ресурс был полностью удален 10 февраля, когда в Google оставалось еще 224 страницы. Что говорить, спустя 5 месяцев там еще остается 2 десятка документов. Гугл очень трепетно относится к проиндексированным страницам и не хочет никак их отпускать .
Сайт №2 (способ запрета файл - robots.txt).

Здесь ситуация разворачивалась интереснее . Яндекс достаточно быстро (меньше чем за месяц) удалил все страницы. Гугл же за месяц выкинул из индекса около 100 документов, потом через месяц еще 200 и практически застыл на месте.
4 апреля мне надоело ждать и я поменял метод запрета с robots.txt на meta name="robots". Это принесло свои плоды - через месяц в базе Google осталось только 160 страниц. Примерно такое же количество остается и по сей день.
Примечателен еще один момент. Несмотря на то, что страницы из индекса удалялись достаточно долго, трафик с поисковиков начал падать значительно быстрее.


Получается, что ПС понимают, что вебмастер запретил ресурс или его документы к индексированию, но почему-то продолжают их там держать .
Выводы
- Яндекс любит больше работу с robots.txt;
- Google любит больше работу с meta name="robots". В связи с тем, что Гугл крайне не любит robots.txt, то универсальным будет именно способ с тегом. Совмещать методы нельзя, потому как, запретив ресурс в robots.txt, поисковый паук не сможет прочитать правила для meta name="robots".
- Зеркало Рунета достаточно быстро удаляет документы при любом методе. Зарубежный поисковик делает это неохотно - очень тяжело добиться полного удаления из базы.
Вот такой получился небольшой эксперимент. Да, конечно, выборка совсем небольшая, но и она смогла подтвердить мои предположения. В прикладном плане это можно использовать, когда есть необходимость закрыть определенные документы для индексирования: предпочтительно использовать meta name="robots" вместо директив в robots.txt.
А какие наблюдения по этой теме есть у вас? Поделитесь своим опытом в комментариях !
Мы выпустили новую книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».

Любому вебмастеру рано или поздно может понадобится удалить сайт из поисковика , или удалить одну страницу . Несмотря на то что дело может показаться простым, возникают некоторые сложности. К примеру, при нажатии на кнопку «удалить» в панели вебмастера, Яндекс может ответить «Нет оснований для удаления». Но только вебмастеру подвластна судьба страниц.
Давайте разбираться.
Как удалить из поиска ненужные страницы?
Для начала разберем как сайт попадает в поиск.
Допустим, вы создали свой сайт, заполнили его контентом и сделали некоторую оптимизацию. Вы ждете, когда придет робот поисковика и просканирует ваш сайт. Сканирование сайта подразумевает, что робот посмотрит ваш сайт и запомнит про что он, грубо говоря. После того как сайт просканирован, он попадает в индекс. Иными словами, просканированный сайт попадает в выдачу поисковиков.
Для управления индексацей страниц вашего сайта, вам необходимо соблюсти обязательные условия:
- Вы зарегистрировали сайт в Яндекс.Вебмастер и имеете доступ к панели вебмастера;
- На сайте есть файл robot.txt.
Заходим в Яндекс.Вебмастер. Для этого нужно ввести в поиске Яндекс Вебмастер или перейти по прямой ссылке .

Выбираем вкладку «Мои сайты». Если у вас он не один, отобразиться список ваших сайтов, тут выбираем сайт, который хотите удалить из поиска
В слайдбаре, который находится справа, находим ссылку «Удалить URL».
Вводим в форме ссылку на страницу и нажимаем «удалить». Яндекс думает, что вы знаете точный адрес страницы, которую хотите удалить. Предполагается, что произойдет удаление введенной вами страницы и все. Но это срабатывает далеко не всегда. Чаще всего это происходит из-за того, что url введенный в форме не соответствует адресу страницы, которую вы хотите удалить из поиска Яндекса .
Как узнать точный URL страницы?
Для того чтобы узнать адреса всех проиндексированных страниц сайта в Яндексе есть специальная команда «host». В строке поиска нужно написать «host:site.ru». Site – здесь пишем адрес вашего сайта. После выполнения данной команды выводится список всех проиндексированных страниц введенного сайта.

А что если страниц в выдаче больше, чем есть на сайте?
Если в выдаче страниц больше, чем у вас на сайте, значит, некоторые страницы имеют дубли – это одна из самых распространенных причин. Для удаления таких страниц есть два решения:
- Закрыть в robots.txt и Яндекс со временем сам удалит ненужные страницы из поиска . Но это может затянуться надолго.
- Удалить дубли вручную.
Для того чтобы удалить страницу из поиска Яндекса вручную:
- Заходим на страницу (дубль).
- Копируем ее адрес.
- Заходим в Яндекс Вебмастер.
- Нажимаем на «Мои сайты».
- Выбираем нужный сайт.
Нажимаем в слайдбаре «Удалить URL » и вставляем в форму адрес дубля страницы.
Возможно, вы увидите такое сообщение:
Как быть в таком случае? Данное сообщение сигнализирует о том, что страница не закрыта от индексации в robots.txt или нет параметра noindex. Закрываем ее и пробуем еще раз. Если все сделано правильно вы увидите такое сообщение.
«URL добавлен в очередь на удаление». Сколько времени займет удаление трудно сказать, зависеть это может как от количества страниц на сайте, так и от самого Яндекса.
Рассказать о статье:

Получите профессиональный взгляд со стороны на свой проект
Специалисты студии SEMANTICA проведут комплексный анализ сайта по следующему плану:
– Технический аудит.
– Оптимизация.
– Коммерческие факторы.
– Внешние факторы.
Мы не просто говорим, в чем проблемы. Мы помогаем их решить
Страницы сайта могут пропадать из результатов поиска Яндекса по нескольким причинам:
- Ошибка при загрузке или обработке страницы роботом - если ответ сервера содержал HTTP-статус 3XX, 4XX или 5XX. Выявить ошибку поможет инструмент Проверка ответа сервера .
- Индексирование страницы запрещено в файле robots.txt или с помощью метатега с директивой noindex .
- Страница перенаправляет робота на другие страницы.
- Страница дублирует содержание другой страницы .
- Страница не является канонической .
Робот продолжает посещать исключенные из поиска страницы, а специальный алгоритм проверяет вероятность их показа в выдаче перед каждым обновлением поисковой базы. Таким образом, страница может появится в поиске в течение двух недель после того, как робот узнает о ее изменении.
Если вы устранили причину удаления страницы, отправьте страницу на переобход . Так вы сообщите роботу об изменениях.
Вопросы и ответы про исключенные из поиска страницы
На странице правильно заполнены метатеги Description, Keywords и элемент title, страница соответствует всем требованиям. Почему она не в поиске?
Алгоритм проверяет на страницах сайта не только наличие всех необходимых тегов, но и уникальность, полноту материала, его востребованность и актуальность, а также многие другие факторы. При этом метатегам стоит уделять внимание. Например, метатег Description и элемент title могут создаваться автоматически, повторять друг друга.
Если на сайте большое количество практически одинаковых товаров, которые отличаются только цветом, размером или конфигурацией, они тоже могут не попасть в поиск. В этот список можно также добавить страницы пагинации, подбора товара или сравнений, страницы-картинки, на которых совсем нет текстового контента.
Страницы, которые отображаются как исключенные, в браузере открываются нормально. Что это значит?
Это может происходить по нескольким причинам:
- Заголовки, которые запрашивает робот у сервера, отличаются от заголовков, запрашиваемых браузером. Поэтому исключенные страницы могут открываться в браузере корректно.
- Если страница исключена из поиска из-за ошибки при ее загрузке, она исчезнет из списка исключенных только в том случае, если при новом обращении робота станет доступна. Проверьте ответ сервера по интересеющему вас URL. Если ответ содержит HTTP-статус 200 OK, дождитесь нового посещения робота.
В списке «Исключенные страницы» показываются страницы, которых уже нет на сайте. Как их удалить?
В разделе Страницы в поиске , в списке Исключенные страницы , отображаются страницы, к которым робот обращался, но не проиндексировал (это могут быть уже несуществующие страницы, если ранее они были известны роботу).
Страница удаляется из списка исключенных, если:
- она недоступна для робота в течение некоторого времени;
- на нее не ссылаются другие страницы сайта и внешние источники.
Наличие и количество исключенных страниц в сервисе не должно влиять на положение сайта в результатах поиска.