Сегодня на каждом углу то тут, то там кричат о пользе нейросетей. А вот что это такое, действительно понимают единицы. Если обратиться за объяснениями к Википедии, голова закружится от высоты понастроенных там цитаделей ученых терминов и определений. Если вы далеки от генной инженерии, а путанный сухой язык вузовских учебников вызывает только потерянность и никаких идей, то попробуем разобраться сообща в проблеме нейросетей.
Чтобы разобраться в проблеме, нужно узнать первопричину, которая кроется совсем на поверхности. Вспоминая Сару Коннор, с содроганием сердца понимаем, что некогда пионеры компьютерных разработок Уоррен Мак-Каллок и Уолтер Питтс преследовали корыстную цель создания первого Искусственного Интеллекта.
Нейронные сети – это электронный прототип самостоятельно обучаемой системы. Как и ребенок, нейросеть впитывает в себя информацию, пережевывает её, приобретает опыт и учится. В процессе обучения такая сеть развивается, растет и может делать собственные выводы и самостоятельно принимать решения.
Если мозг человека состоит из нейронов, то условно договоримся, что электронный нейрон – это некая воображаемая коробочка, у которой множество входных отверстий, а выходное – одно. Внутренний алгоритм нейрона определяется порядок обработки и анализа полученной информации и преобразования её в единый полезный ком знаний. В зависимости от того, насколько хорошо работают входы и выходы, вся система или соображает быстро, или, наоборот, может тормозить.
Важно : Как правило, в нейронных сетях используется аналоговая информация.
Повторимся, что входных потоков информации (по-научному эту связь первоначальной информации и наш “нейрон” называют синапсами) может быть множество, и все они носят разных характер и имеют неравную значимость. Например, человек воспринимает окружающий мир через органы зрения, осязания и обоняния. Логично, что зрение первостепеннее обоняния. Исходя из разных жизненных ситуаций мы используем определенные органы чувств: в полной темноте на первый план выходят осязание и слух. Синапсы у нейросетей по такой же аналогии в различных ситуациях будут иметь разную значимость, которую принято обозначать весом связи. При написании кода устанавливается минимальный порог прохождения информации. Если вес связи выше заданного значения, то результат проверки нейроном положительный (и равен единице в двоичной системе), если меньше – то отрицательный. Логично, что, чем выше задана планка, тем точнее будет работа нейросети, но тем дольше она будет проходить.
Чтобы нейронная сеть работала корректно, нужно потратить время на её обучение – это и есть главное отличие от простых программируемых алгоритмов. Как и маленькому ребенку, нейросети нужна начальная информационная база, но если написать первоначальный код корректно, то нейросеть уже сама сможет не просто делать верный выбор из имеющейся информации, но и строить самостоятельные предположения.
При написании первичного кода объяснять свои действия нужно буквально по пальцам. Если мы работаем, например, с изображениями, то на первом этапе значение для нас будет иметь её размер и класс. Если первая характеристика подскажет нам количество входов, то вторая поможет самой нейросети разобраться с информацией. В идеале, загрузив первичные данные и сопоставив топологию классов, нейросеть далее уже сама сможет классифицировать новую информацию. Допустим, мы решили загрузить изображение 3х5 пикселей. Простая арифметика нам подскажет, что входов будет: 3*5=15. А сама классификация определит общее количество выходов, т.е. нейронов. Другой пример: нейросети необходимо распознать букву “С”. Заданный порог – полное соответствие букве, для этого потребуется один нейрон с количеством входов, равных размеру изображения.
Допустим, что размер будет тот же 3х5 пикселей. Скармливая программе различные картинки букв или цифр, будем учить её определять изображение нужного нам символа.
Как и в любом обучении, ученика за неправильный ответ нужно наказывать, а за верный мы ничего давать не будем. Если верный ответ программа воспринимает как False, то увеличиваем вес входа на каждом синапсе. Если же, наоборот, при неверном результате программа считает результат положительным или True, то вычитаем вес из каждого входа в нейрон. Начать обучение логичнее со знакомства с нужным нам символом. Первый результат будет неверным, однако немного подкорректировав код, при дальнейшей работе программа будет работать корректно. Приведенный пример алгоритма построения кода для нейронной сети называется парцетроном.

Бывают и более сложные варианты работы нейросетей с возвратом неверных данных, их анализом и логическими выводами самой сети. Например, онлайн-предсказатель будущего вполне себе запрограммированная нейросеть. Такие проги способны обучаться как с учителем, так и без него, и носят название адаптивного резонанса. Их суть заключается в том, что у нейронов уже есть свои представления об ожидании о том, какую именно информацию они хотят получить и в каком виде. Между ожиданием и реальностью проходит тонкий порог так называемой бдительности нейронов, которая и помогает сети правильно классифицировать поступающую информацию и не упускать ни пикселя. Фишка АР нейросети в том, что учится она самостоятельно с самого начала, самостоятельно определяет порог бдительности нейронов. Что, в свою очередь, играет роль при классифицировании информации: чем бдительнее сеть, тем она дотошнее.
Самые азы знаний о том, что такое нейросети, мы получили. Теперь попробуем обобщить полученную информацию. Итак, нейросети – это электронный прототип мышлению человека. Они состоят из электронных нейронов и синапсов – потоков информации на входе и выходе из нейрона. Программируются нейросети по принципу обучения с учителем (программистом, который закачивает первичную информацию) или же самостоятельно (основываясь на предположения и ожидания от полученную информацию, которую определяет всё тот же программист). С помощью нейросети можно создать любую систему: от простого определения рисунка на пиксельных изображениях до психодиагностики и экономической аналитики.

Доброго времени вам суток, уважаемое Хабрасообщество.
Хочу вначале сделать маленький дисклеймер. Предыдущим постом в этом сообществе были рассмотрены основы искусственной нейронной сети. Я данной темой занималась для написания своей магистерской работы и соответственно прочитала в свое время достаточно литературы, поэтому мне бы хотелось немного дополнить и в дальнейшем продолжить вам рассказывать о том, что такое нейронная сеть, какое представление она имеет изнутри, как с ее помощью решают задачи и так далее…
Сразу оговорюсь, что я не гуру в данном вопросе, я его знаю (ну или знала, так как времени прошло уже достаточно) настолько глубоко, насколько мне было это необходимо для написания работающей нейронной сети для распознавания цифр, ее обучения и дальнейшего использования. Предметом исследования была структура нейронной сети для распознавания символов, а конкретно, зависимость между количеством нейронов в скрытом слое и сложностью выборки для входных данных (количеством символов для распознавания).
UPD
: данный текст в основном является обобщением из прочитанной литературы. Он не
написан мною лично. По крайней мере эта часть.
UPD2
: Скорей всего продолжения данной темы не будет, так как хабрапользователь , который является смотрителем данного блога, считает, что нет смысла писать здесь то, что можно прочитать из многочисленной литературы, которая есть по нейронным сетям. Так что извините.
Возможно первая часть будет в чем-то похожа на предыдущий пост хабрапользователя , но я считаю, что стоит более детально рассмотреть строение искусственного нейрона, у меня есть, что добавить, ну и, плюс ко всему, я хочу написать полноценную и законченную серию постов про нейросети, не опираясь на уже написанное. Надеюсь вам будет полезен данный материал.
Биологический прототип нейрона
Первой попыткой создания и исследования искусственных нейронных сетей считается работа Дж. Маккалока (J. McCulloch) и У. Питтса (W. Pitts) «Логическое исчисление идей, относящихся к нервной деятельности» (1943 г.), в которой были сформулированы основные принципы построения искусственных нейронов и нейронных сетей. И хотя эта работа была лишь первым этапом, многие идеи, описанные в ней, остаются актуальными и на сегодняшний день.
Искусственные нейронные сети индуцированы биологией, потому что они состоят из элементов, функциональные возможности которых аналогичны большинству функций биологического нейрона. Эти элементы можно организовать таким образом, который может соответствовать анатомии мозга, и они демонстрируют большое количество свойств, которые присущие мозгу. Например, они могут учиться на основе опыта, могут обобщать предыдущие прецеденты на новые случаи и выявлять существенные особенности из входных данных, которые содержат избыточную информацию.
Центральная нервная система имеет клеточное строение. Единица - нервная клетка, нейрон. Он состоит из тела и отростков, которые соединяют его с внешним миром (рис. 1.1). Отростки, по которым нейрон получает возбуждение, называются дендритами. Отросток, по которому нейрон передает возбуждение, называется аксоном, причем аксон у каждого нейрона один. Дендриты и аксон имеют довольно сложную ветвистую структуру. Место соединения аксона нейрона - источника возбуждения с дендритом называется синапсом. Основная функция нейрона состоит в передаче возбуждения из дендритов в аксон. Но сигналы, которые поступают из разных дендритов, могут влиять на сигнал в аксоне. Нейрон выдаст сигнал, если суммарное возбуждение превысит некоторое предельное значение, которое в общем случае меняется в некоторых границах. В противном случае на аксон сигнал выдан не будет: нейрон не ответит на возбуждение. У этой основной схемы много осложнений и исключений, однако большинство нейронных сетей моделируют именно эти простые свойства.
(рисунок 1.1) - Модель биологического нейрона
Нейрон имеет следующие основные свойства:
- Принимает участие в обмене веществ и рассеивает энергию. Меняет внутреннее состояние со временем, реагирует на входные сигналы, формирует выходные воздействия и поэтому является активной динамической системой.
- Имеет множество синапсов - контактов для передачи информации
Интенсивность сигнала, который получает нейрон (а следовательно и возможность его активации), сильно зависит от активности синапсов. Каждый синапс имеет длину, и специальные химические вещества передают сигнал вдоль него. Один из самых авторитетных исследователей нейросистем, Дональд Хебб, высказал постулат, что обучение состоит в первую очередь в изменениях «силы» синаптических связей. Например, в классическом опыте Павлова, каждый раз непосредственно перед кормлением собаки звонил колокольчик, и собака быстро научилась связывать звонок колокольчика с пищей. Синаптические связи между участками коры главного мозга, ответственными за слух, и слюнными железами усилились, и при возбуждении коры звуком колокольчика у собаки начиналось слюноотделение.
Таким образом, будучи построенный из очень большого числа совсем простых элементов (каждый из которых берет взвешенную сумму входных сигналов и в случае, если суммарный вход превышает определенный уровень, передает дальше двоичный сигнал), мозг способен решать чрезвычайно сложные задачи.
Искуственный нейрон
Искусственный нейрон имитирует в первом приближении свойства биологического нейрона. На вход искусственного нейрона поступает некоторое множество сигналов, каждый с которых является выходом другого нейрона. Каждый вход множится на соответствующий вес, аналогичный синаптической силе, и все произведения суммируются, определяя уровень активации нейрона. На рисунке 1.2 представлена модель, которая реализует эту идею. Хотя сети бывают довольно разные, в основе почти всех их лежит эта конфигурация. Здесь множество входных сигналов, обозначенных x1, x2, ..., xn, поступают на искусственный нейрон. Эти входные сигналы отвечают сигналам, которые приходят в синапсы биологического нейрона. Каждый сигнал множится на соответствующий вес w1, w2,..., wn, и поступает на суммирующий блок, обозначенный ∑. Каждый вес отвечает «силе» одной биологической синаптической связи. Суммирующий блок, который соответствует телу биологического элемента, алгебраически объединяет взвешенные входы, создавая выход NET:
(рисунок 1.2) - Искусственный нейрон в первом приближении
Данное описание можно представить следующей формулой
где w0 - биас;
wі - вес i- го нейрона;
xі - выход i- го нейрона;
n - количество нейронов, которые входят в обрабатываемый нейрон
Сигнал w0, который имеет название биас, отображает функцию предельного значения, сдвига. Этот сигнал позволяет сдвинуть начало отсчета функции активации, которая в дальнейшем приводит к увеличению скорости обучения. Этот сигнал добавляется к каждому нейрону, он учится как и все другие весы, а его особенность в том, что он подключается к сигналу +1, а не к выходу предыдущего нейрона.
Полученный сигнал NET как правило обрабатывается функцией активации и дает выходной нейронный сигнал OUT (рис. 1.3)

(рисунок 1.3) - Искусственный нейрон с функцией активации
Если функция активации суживает диапазон изменения величины NET так, что при каждом значении NET значения OUT принадлежат некоторому диапазону - конечному интервалу, то функция F называется функцией, которая суживает. В качестве этой функции часто используются логистическая или «сигмоидальная» функция. Эта функция математически выражается следующим образом:
Основное преимущество такой функции - то, что она имеет простую производную и дифференцируется по всей оси абсцисс. График функции имеет следующий вид (рис. 1.4)

(рисунок 1.4) - Вид сигмоидальной функции активации
Функция усиливает слабые сигналы и предотвращает насыщение от больших сигналов.
Другой функцией, которая также часто используется, является гиперболический тангенс. По форме она похожа на сигмоидальную и часто используется биологами в качестве математической модели активации нервной клетки. Она имеет вид
![]()
Как и логистическая функция, гиперболический тангенс имеет S-образный вид, но он является симметричным относительно начала координат, и в точке NET=0 значение выходного сигнала OUT=0 (рис. 1.5). На графике можно увидеть, что эта функция, в отличии от логистической, принимает значение разных знаков, что является очень выгодным свойством для некоторых типов сетей.

(рисунок 1.5) - Вид функции активации - гиперболический тангенс
Рассмотренная модель искусственного нейрона игнорирует много свойств биологического нейрона. Например, она не принимает во внимание задержки во времени, которые влияют на динамику системы. Входные сигналы сразу порождают исходные. Но несмотря на это, искусственные нейронные сети, составленные из рассмотренных нейронов, выявляют свойства, которые присущи биологической системе.
ссылки на литературу:
1. Ф. Уоссермен. Нейрокомпьютерная техника: теория и практика. Перевод на русский язык Ю. А. Зуев, В. А. Точенов, 1992
2. И. В. Заенцев. Нейронные сети: основные модели. Учебное пособие к курсу “Нейронные сети”

Добро пожаловать во вторую часть руководства по нейронным сетям. Сразу хочу принести извинения всем кто ждал вторую часть намного раньше. По определенным причинам мне пришлось отложить ее написание. На самом деле я не ожидал, что у первой статьи будет такой спрос и что так много людей заинтересует данная тема. Взяв во внимание ваши комментарии, я постараюсь предоставить вам как можно больше информации и в то же время сохранить максимально понятный способ ее изложения. В данной статье, я буду рассказывать о способах обучения/тренировки нейросетей (в частности метод обратного распространения) и если вы, по каким-либо причинам, еще не прочитали первую часть , настоятельно рекомендую начать с нее. В процессе написания этой статьи, я хотел также рассказать о других видах нейросетей и методах тренировки, однако, начав писать про них, я понял что это пойдет вразрез с моим методом изложения. Я понимаю, что вам не терпится получить как можно больше информации, однако эти темы очень обширны и требуют детального анализа, а моей основной задачей является не написать очередную статью с поверхностным объяснением, а донести до вас каждый аспект затронутой темы и сделать статью максимально легкой в освоении. Спешу расстроить любителей “покодить”, так как я все еще не буду прибегать к использованию языка программирования и буду объяснять все “на пальцах”. Достаточно вступления, давайте теперь продолжим изучение нейросетей.
Что такое нейрон смещения?

Перед тем как начать нашу основную тему, мы должны ввести понятие еще одного вида нейронов - нейрон смещения. Нейрон смещения или bias нейрон - это третий вид нейронов, используемый в большинстве нейросетей. Особенность этого типа нейронов заключается в том, что его вход и выход всегда равняются 1 и они никогда не имеют входных синапсов. Нейроны смещения могут, либо присутствовать в нейронной сети по одному на слое, либо полностью отсутствовать, 50/50 быть не может (красным на схеме обозначены веса и нейроны которые размещать нельзя). Соединения у нейронов смещения такие же, как у обычных нейронов - со всеми нейронами следующего уровня, за исключением того, что синапсов между двумя bias нейронами быть не может. Следовательно, их можно размещать на входном слое и всех скрытых слоях, но никак не на выходном слое, так как им попросту не с чем будет формировать связь.
Для чего нужен нейрон смещения?

Нейрон смещения нужен для того, чтобы иметь возможность получать выходной результат, путем сдвига графика функции активации вправо или влево. Если это звучит запутанно, давайте рассмотрим простой пример, где есть один входной нейрон и один выходной нейрон. Тогда можно установить, что выход O2 будет равен входу H1, умноженному на его вес, и пропущенному через функцию активации (формула на фото слева). В нашем конкретном случае, будем использовать сигмоид.
Из школьного курса математики, мы знаем, что если взять функцию y = ax+b и менять у нее значения “а”, то будет изменяться наклон функции (цвета линий на графике слева), а если менять “b”, то мы будем смещать функцию вправо или влево (цвета линий на графике справа). Так вот “а” - это вес H1, а “b” - это вес нейрона смещения B1. Это грубый пример, но примерно так все и работает (если вы посмотрите на функцию активации справа на изображении, то заметите очень сильное сходство между формулами). То есть, когда в ходе обучения, мы регулируем веса скрытых и выходных нейронов, мы меняем наклон функции активации. Однако, регулирование веса нейронов смещения может дать нам возможность сдвинуть функцию активации по оси X и захватить новые участки. Иными словами, если точка, отвечающая за ваше решение, будет находиться, как показано на графике слева, то ваша НС никогда не сможет решить задачу без использования нейронов смещения. Поэтому, вы редко встретите нейронные сети без нейронов смещения.
Также нейроны смещения помогают в том случае, когда все входные нейроны получают на вход 0 и независимо от того какие у них веса, они все передадут на следующий слой 0, но не в случае присутствия нейрона смещения. Наличие или отсутствие нейронов смещения - это гиперпараметр (об этом чуть позже). Одним словом, вы сами должны решить, нужно ли вам использовать нейроны смещения или нет, прогнав НС с нейронами смешения и без них и сравнив результаты.
ВАЖНО знать, что иногда на схемах не обозначают нейроны смещения, а просто учитывают их веса при вычислении входного значения например:
Input = H1*w1+H2*w2+b3
b3 = bias*w3
Так как его выход всегда равен 1, то можно просто представить что у нас есть дополнительный синапс с весом и прибавить к сумме этот вес без упоминания самого нейрона.
Как сделать чтобы НС давала правильные ответы?
Ответ прост - нужно ее обучать. Однако, насколько бы прост не был ответ, его реализация в плане простоты, оставляет желать лучшего. Существует несколько методов обучения НС и я выделю 3, на мой взгляд, самых интересных:- Метод обратного распространения (Backpropagation)
- Метод упругого распространения (Resilient propagation или Rprop)
- Генетический Алгоритм (Genetic Algorithm)
Что такое градиентный спуск?
Это способ нахождения локального минимума или максимума функции с помощью движения вдоль градиента. Если вы поймете суть градиентного спуска, то у вас не должно возникнуть никаких вопросов во время использования метода обратного распространения. Для начала, давайте разберемся, что такое градиент и где он присутствует в нашей НС. Давайте построим график, где по оси х будут значения веса нейрона(w) а по оси у - ошибка соответствующая этому весу(e).
Посмотрев на этот график, мы поймем, что график функция f(w) является зависимостью ошибки от выбранного веса. На этом графике нас интересует глобальный минимум - точка (w2,e2) или, иными словами, то место где график подходит ближе всего к оси х. Эта точка будет означать, что выбрав вес w2 мы получим самую маленькую ошибку - e2 и как следствие, самый лучший результат из всех возможных. Найти же эту точку нам поможет метод градиентного спуска (желтым на графике обозначен градиент). Соответственно у каждого веса в нейросети будет свой график и градиент и у каждого надо найти глобальный минимум.
Так что же такое, этот градиент? Градиент - это вектор который определяет крутизну склона и указывает его направление относительно какой либо из точек на поверхности или графике. Чтобы найти градиент нужно взять производную от графика по данной точке (как это и показано на графике). Двигаясь по направлению этого градиента мы будем плавно скатываться в низину. Теперь представим что ошибка - это лыжник, а график функции - гора. Соответственно, если ошибка равна 100%, то лыжник находиться на самой вершине горы и если ошибка 0% то в низине. Как все лыжники, ошибка стремится как можно быстрее спуститься вниз и уменьшить свое значение. В конечном случае у нас должен получиться следующий результат:

Представьте что лыжника забрасывают, с помощью вертолета, на гору. На сколько высоко или низко зависит от случая (аналогично тому, как в нейронной сети при инициализации веса расставляются в случайном порядке). Допустим ошибка равна 90% и это наша точка отсчета. Теперь лыжнику нужно спуститься вниз, с помощью градиента. На пути вниз, в каждой точке мы будем вычислять градиент, что будет показывать нам направление спуска и при изменении наклона, корректировать его. Если склон будет прямым, то после n-ого количества таких действий мы доберемся до низины. Но в большинстве случаев склон (график функции) будет волнистый и наш лыжник столкнется с очень серьезной проблемой - локальный минимум. Я думаю все знают, что такое локальный и глобальный минимум функции, для освежения памяти вот пример. Попадание в локальный минимум чревато тем, что наш лыжник навсегда останется в этой низине и никогда не скатиться с горы, следовательно мы никогда не сможем получить правильный ответ. Но мы можем избежать этого, снарядив нашего лыжника реактивным ранцем под названием момент (momentum). Вот краткая иллюстрация момента:

Как вы уже наверное догадались, этот ранец придаст лыжнику необходимое ускорение чтобы преодолеть холм, удерживающий нас в локальном минимуме, однако здесь есть одно НО. Представим что мы установили определенное значение параметру момент и без труда смогли преодолеть все локальные минимумы, и добраться до глобального минимума. Так как мы не можем просто отключить реактивный ранец, то мы можем проскочить глобальный минимум, если рядом с ним есть еще низины. В конечном случае это не так важно, так как рано или поздно мы все равно вернемся обратно в глобальный минимум, но стоит помнить, что чем больше момент, тем больше будет размах с которым лыжник будет кататься по низинам. Вместе с моментом в методе обратного распространения также используется такой параметр как скорость обучения (learning rate). Как наверняка многие подумают, чем больше скорость обучения, тем быстрее мы обучим нейросеть. Нет. Скорость обучения, также как и момент, является гиперпараметром - величина которая подбирается путем проб и ошибок. Скорость обучения можно напрямую связать со скоростью лыжника и можно с уверенностью сказать - тише едешь дальше будешь. Однако здесь тоже есть определенные аспекты, так как если мы совсем не дадим лыжнику скорости то он вообще никуда не поедет, а если дадим маленькую скорость то время пути может растянуться на очень и очень большой период времени. Что же тогда произойдет если мы дадим слишком большую скорость?

Как видите, ничего хорошего. Лыжник начнет скатываться по неправильному пути и возможно даже в другом направлении, что как вы понимаете только отдалит нас от нахождения правильного ответа. Поэтому во всех этих параметрах нужно находить золотую середину чтобы избежать не сходимости НС (об этом чуть позже).
Что такое Метод Обратного Распространения (МОР)?
Вот мы и дошли до того момента, когда мы можем обсудить, как же все таки сделать так, чтобы ваша НС могла правильно обучаться и давать верные решения. Очень хорошо МОР визуализирован на этой гифке:
А теперь давайте подробно разберем каждый этап. Если вы помните то в предыдущей статье мы считали выход НС. По другому это называется передача вперед (Forward pass), то есть мы последовательно передаем информацию от входных нейронов к выходным. После чего мы вычисляем ошибку и основываясь на ней делаем обратную передачу, которая заключается в том, чтобы последовательно менять веса нейронной сети, начиная с весов выходного нейрона. Значение весов будут меняться в ту сторону, которая даст нам наилучший результат. В моих вычисления я буду пользоваться методом нахождения дельты, так как это наиболее простой и понятный способ. Также я буду использовать стохастический метод обновления весов (об этом чуть позже).
Теперь давайте продолжим с того места, где мы закончили вычисления в предыдущей статье.
Данные задачи из предыдущей статьи

Данные: I1=1, I2=0, w1=0.45, w2=0.78 ,w3=-0.12 ,w4=0.13 ,w5=1.5 ,w6=-2.3.
H1input = 1*0.45+0*-0.12=0.45
H1output = sigmoid(0.45)=0.61
H2input = 1*0.78+0*0.13=0.78
H2output = sigmoid(0.78)=0.69
O1input = 0.61*1.5+0.69*-2.3=-0.672
O1output = sigmoid(-0.672)=0.33
O1ideal = 1 (0xor1=1)
Error = ((1-0.33)^2)/1=0.45
Результат - 0.33, ошибка - 45%.
Так как мы уже подсчитали результат НС и ее ошибку, то мы можем сразу приступить к МОРу. Как я уже упоминал ранее, алгоритм всегда начинается с выходного нейрона. В таком случае давайте посчитаем для него значение? (дельта) по формуле 1.
 Так как у выходного нейрона нет исходящих синапсов, то мы будем пользоваться первой формулой (? output), следственно для скрытых нейронов мы уже будем брать вторую формулу (? hidden). Тут все достаточно просто: считаем разницу между желаемым и полученным результатом и умножаем на производную функции активации от входного значения данного нейрона. Прежде чем приступить к вычислениям я хочу обратить ваше внимание на производную. Во первых как это уже наверное стало понятно, с МОР нужно использовать только те функции активации, которые могут быть дифференцированы. Во вторых чтобы не делать лишних вычислений, формулу производной можно заменить на более дружелюбную и простую формула вида:
Так как у выходного нейрона нет исходящих синапсов, то мы будем пользоваться первой формулой (? output), следственно для скрытых нейронов мы уже будем брать вторую формулу (? hidden). Тут все достаточно просто: считаем разницу между желаемым и полученным результатом и умножаем на производную функции активации от входного значения данного нейрона. Прежде чем приступить к вычислениям я хочу обратить ваше внимание на производную. Во первых как это уже наверное стало понятно, с МОР нужно использовать только те функции активации, которые могут быть дифференцированы. Во вторых чтобы не делать лишних вычислений, формулу производной можно заменить на более дружелюбную и простую формула вида:
Таким образом наши вычисления для точки O1 будут выглядеть следующим образом.
Решение
O1output = 0.33
O1ideal = 1
Error = 0.45
O1 = (1 - 0.33) * ((1 - 0.33) * 0.33) = 0.148
На этом вычисления для нейрона O1 закончены. Запомните, что после подсчета дельты нейрона мы обязаны сразу обновить веса всех исходящих синапсов этого нейрона. Так как в случае с O1 их нет, мы переходим к нейронам скрытого уровня и делаем тоже самое за исключение того, что формула подсчета дельты у нас теперь вторая и ее суть заключается в том, чтобы умножить производную функции активации от входного значения на сумму произведений всех исходящих весов и дельты нейрона с которой этот синапс связан. Но почему формулы разные? Дело в том что вся суть МОР заключается в том чтобы распространить ошибку выходных нейронов на все веса НС. Ошибку можно вычислить только на выходном уровне, как мы это уже сделали, также мы вычислили дельту в которой уже есть эта ошибка. Следственно теперь мы будем вместо ошибки использовать дельту которая будет передаваться от нейрона к нейрону. В таком случае давайте найдем дельту для H1:
Решение
H1output = 0.61
w5 = 1.5
?O1 = 0.148
H1 = ((1 - 0.61) * 0.61) * (1.5 * 0.148) = 0.053
Теперь нам нужно найти градиент для каждого исходящего синапса. Здесь обычно вставляют 3 этажную дробь с кучей производных и прочим математическим адом, но в этом и вся прелесть использования метода подсчета дельт, потому что в конечном счете ваша формула нахождения градиента будет выглядеть вот так:
Здесь точка A это точка в начале синапса, а точка B на конце синапса. Таким образом мы можем подсчитать градиент w5 следующим образом:
Решение
H1output = 0.61
?O1 = 0.148
GRADw5 = 0.61 * 0.148 = 0.09
Сейчас у нас есть все необходимые данные чтобы обновить вес w5 и мы сделаем это благодаря функции МОР которая рассчитывает величину на которую нужно изменить тот или иной вес и выглядит она следующим образом:
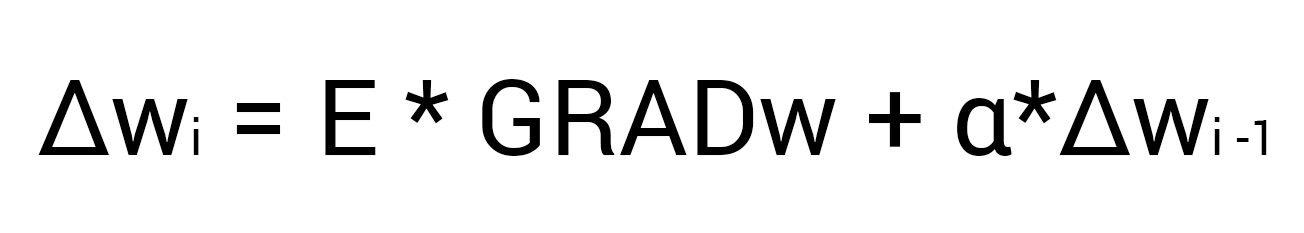
Настоятельно рекомендую вам не игнорировать вторую часть выражения и использовать момент так как это вам позволит избежать проблем с локальным минимумом.
Здесь мы видим 2 константы о которых мы уже говорили, когда рассматривали алгоритм градиентного спуска: E (эпсилон) - скорость обучения, ? (альфа) - момент. Переводя формулу в слова получим: изменение веса синапса равно коэффициенту скорости обучения, умноженному на градиент этого веса, прибавить момент умноженный на предыдущее изменение этого веса (на 1-ой итерации равно 0). В таком случае давайте посчитаем изменение веса w5 и обновим его значение прибавив к нему?w5.
Решение
E = 0.7
? = 0.3
w5 = 1.5
GRADw5 = 0.09
?w5(i-1) = 0
W5 = 0.7 * 0.09 + 0 * 0.3 = 0.063
w5 = w5 + ?w5 = 1.563
Таким образом после применения алгоритма наш вес увеличился на 0.063. Теперь предлагаю сделать вам тоже самое для H2.
Решение
H2output = 0.69
w6 = -2.3
?O1 = 0.148
E = 0.7
? = 0.3
?w6(i-1) = 0
H2 = ((1 - 0.69) * 0.69) * (-2.3 * 0.148) = -0.07
GRADw6 = 0.69 * 0.148 = 0.1
W6 = 0.7 * 0.1 + 0 * 0.3 = 0.07
W6 = w6 + ?w6 = -2.2
И конечно не забываем про I1 и I2, ведь у них тоже есть синапсы веса которых нам тоже нужно обновить. Однако помним, что нам не нужно находить дельты для входных нейронов так как у них нет входных синапсов.
Решение
w1 = 0.45, ?w1(i-1) = 0
w2 = 0.78, ?w2(i-1) = 0
w3 = -0.12, ?w3(i-1) = 0
w4 = 0.13, ?w4(i-1) = 0
?H1 = 0.053
?H2 = -0.07
E = 0.7
? = 0.3
GRADw1 = 1 * 0.053 = 0.053
GRADw2 = 1 * -0.07 = -0.07
GRADw3 = 0 * 0.053 = 0
GRADw4 = 0 * -0.07 = 0
W1 = 0.7 * 0.053 + 0 * 0.3 = 0.04
?w2 = 0.7 * -0.07 + 0 * 0.3 = -0.05
?w3 = 0.7 * 0 + 0 * 0.3 = 0
?w4 = 0.7 * 0 + 0 * 0.3 = 0
W1 = w1 + ?w1 = 0.5
w2 = w2 + ?w2 = 0.73
w3 = w3 + ?w3 = -0.12
w4 = w4 + ?w4 = 0.13
Теперь давайте убедимся в том, что мы все сделали правильно и снова посчитаем выход НС только уже с обновленными весами.
Решение
I1 = 1
I2 = 0
w1 = 0.5
w2 = 0.73
w3 = -0.12
w4 = 0.13
w5 = 1.563
w6 = -2.2
H1input = 1 * 0.5 + 0 * -0.12 = 0.5
H1output = sigmoid(0.5) = 0.62
H2input = 1 * 0.73 + 0 * 0.124 = 0.73
H2output = sigmoid(0.73) = 0.675
O1input = 0.62* 1.563 + 0.675 * -2.2 = -0.51
O1output = sigmoid(-0.51) = 0.37
O1ideal = 1 (0xor1=1)
Error = ((1-0.37)^2)/1=0.39
Результат - 0.37, ошибка - 39%.
Как мы видим после одной итерации МОР, нам удалось уменьшить ошибку на 0.04 (6%). Теперь нужно повторять это снова и снова, пока ваша ошибка не станет достаточно мала.
Что еще нужно знать о процессе обучения?
Нейросеть можно обучать с учителем и без (supervised, unsupervised learning).Обучение с учителем - это тип тренировок присущий таким проблемам как регрессия и классификация (им мы и воспользовались в примере приведенном выше). Иными словами здесь вы выступаете в роли учителя а НС в роли ученика. Вы предоставляете входные данные и желаемый результат, то есть ученик посмотрев на входные данные поймет, что нужно стремиться к тому результату который вы ему предоставили.
Обучение без учителя - этот тип обучения встречается не так часто. Здесь нет учителя, поэтому сеть не получает желаемый результат или же их количество очень мало. В основном такой вид тренировок присущ НС у которых задача состоит в группировке данных по определенным параметрам. Допустим вы подаете на вход 10000 статей на хабре и после анализа всех этих статей НС сможет распределить их по категориям основываясь, например, на часто встречающихся словах. Статьи в которых упоминаются языки программирования, к программированию, а где такие слова как Photoshop, к дизайну.
Существует еще такой интересный метод, как обучение с подкреплением (reinforcement learning). Этот метод заслуживает отдельной статьи, но я попытаюсь вкратце описать его суть. Такой способ применим тогда, когда мы можем основываясь на результатах полученных от НС, дать ей оценку. Например мы хотим научить НС играть в PAC-MAN, тогда каждый раз когда НС будет набирать много очков мы будем ее поощрять. Иными словами мы предоставляем НС право найти любой способ достижения цели, до тех пор пока он будет давать хороший результат. Таким способом, сеть начнет понимать чего от нее хотят добиться и пытается найти наилучший способ достижения этой цели без постоянного предоставления данных “учителем”.
Также обучение можно производить тремя методами: стохастический метод (stochastic), пакетный метод (batch) и мини-пакетный метод (mini-batch). Существует очень много статей и исследований на тему того, какой из методов лучше и никто не может прийти к общему ответу. Я же сторонник стохастического метода, однако я не отрицаю тот факт, что каждый метод имеет свои плюсы и минусы.
Вкратце о каждом методе:
Стохастический (его еще иногда называют онлайн) метод работает по следующему принципу - нашел?w, сразу обнови соответствующий вес.
Пакетный метод же работает по другому. Мы суммируем?w всех весов на текущей итерации и только потом обновляем все веса используя эту сумму. Один из самых важных плюсов такого подхода - это значительная экономия времени на вычисление, точность же в таком случае может сильно пострадать.
Мини-пакетный метод является золотой серединой и пытается совместить в себе плюсы обоих методов. Здесь принцип таков: мы в свободном порядке распределяем веса по группам и меняем их веса на сумму?w всех весов в той или иной группе.
Что такое гиперпараметры?
Гиперпараметры - это значения, которые нужно подбирать вручную и зачастую методом проб и ошибок. Среди таких значений можно выделить:- Момент и скорость обучения
- Количество скрытых слоев
- Количество нейронов в каждом слое
- Наличие или отсутствие нейронов смещения
Что такое сходимость?

Сходимость говорит о том, правильная ли архитектура НС и правильно ли были подобраны гиперпараметры в соответствии с поставленной задачей. Допустим наша программа выводит ошибку НС на каждой итерации в лог. Если с каждой итерацией ошибка будет уменьшаться, то мы на верном пути и наша НС сходится. Если же ошибка будет прыгать вверх - вниз или застынет на определенном уровне, то НС не сходится. В 99% случаев это решается изменением гиперпараметров. Оставшийся 1% будет означать, что у вас ошибка в архитектуре НС. Также бывает, что на сходимость влияет переобучение НС.
Что такое переобучение?
Переобучение, как следует из названия, это состояние нейросети, когда она перенасыщена данными. Это проблема возникает, если слишком долго обучать сеть на одних и тех же данных. Иными словами, сеть начнет не учиться на данных, а запоминать и “зубрить” их. Соответственно, когда вы уже будете подавать на вход этой НС новые данные, то в полученных данных может появиться шум, который будет влиять на точность результата. Например, если мы будем показывать НС разные фотографии яблок (только красные) и говорить что это яблоко. Тогда, когда НС увидит желтое или зеленое яблоко, оно не сможет определить, что это яблоко, так как она запомнила, что все яблоки должны быть красными. И наоборот, когда НС увидит что-то красное и по форме совпадающее с яблоком, например персик, она скажет, что это яблоко. Это и есть шум. На графике шум будет выглядеть следующим образом.
Видно, что график функции сильно колеблется от точки к точке, которые являются выходными данными (результатом) нашей НС. В идеале, этот график должен быть менее волнистый и прямой. Чтобы избежать переобучения, не стоит долго тренировать НС на одних и тех же или очень похожих данных. Также, переобучение может быть вызвано большим количеством параметров, которые вы подаете на вход НС или слишком сложной архитектурой. Таким образом, когда вы замечаете ошибки (шум) в выходных данных после этапа обучения, то вам стоит использовать один из методов регуляризации, но в большинстве случаев это не понадобиться.
Заключение
Надеюсь эта статья смогла прояснить ключевые моменты такого нелегко предмета, как Нейронные сети. Однако я считаю, что сколько бы ты статей не прочел, без практики такую сложную тему освоить невозможно. Поэтому, если вы только в начале пути и хотите изучить эту перспективную и развивающуюся отрасль, то советую начать практиковаться с написания своей НС, а уже после прибегать к помощи различных фреймворков и библиотек. Также, если вам интересен мой метод изложения информации и вы хотите, чтобы я написал статьи на другие темы связанные с Машинным обучением, то проголосуйте в опросе ниже за ту тему которую вам интересна. До встречи в будущих статьях:)Вопросы искусственного интеллекта и нейронных сетей в настоящее время становится популярным, как никогда ранее. Множество пользователей все чаще и чаще обращаются в с вопросами о том, как работают нейронные сети, что они из себя представляют и на чём построен принцип их деятельности?
Эти вопросы вместе с популярностью имеют и немалую сложность, так как процессы представляют собой сложные алгоритмы машинного обучения, предназначенные для различных целей, от анализа изменений до моделирования рисков, связанных с определёнными действиями.
Что такое нейронные сети и их типы?
Первый вопрос, который возникает у интересующихся, что же такое нейронная сеть? В классическом определении это определённая последовательность нейронов, которые объединены между собой синапсами. Нейронные сети являются упрощённой моделью биологических аналогов.
Программа, имеющая структуру нейронной сети, даёт возможность машине анализировать входные данные и запоминать результат, полученный из определённых исходников. В последующем подобный подход позволяет извлечь из памяти результат, соответствующий текущему набору данных, если он уже имелся в опыте циклов сети.
Многие воспринимают нейронную сеть, как аналог человеческого мозга. С одной стороны, можно считать это суждение близким к истине, но, с другой стороны, человеческий мозг слишком сложный механизм, чтобы была возможность воссоздать его с помощью машины хотя бы на долю процента. Нейронная сеть — это в первую очередь программа, основанная на принципе действия головного мозга, но никак не его аналог.
Нейронная сеть представляет собой связку нейронов, каждый из которых получает информацию, обрабатывает её и передаёт другому нейрону. Каждый нейрон обрабатывает сигнал совершенно одинаково.
Как тогда получается различный результат? Все дело в синапсах, которые соединяют нейроны друг с другом. Один нейрон может иметь огромное количество синапсов, усиливающих или ослабляющих сигнал, при этом они имеют особенность изменять свои характеристики с течением времени.
Именно правильно выбранные параметры синапсов дают возможность получить на выходе правильный результат преобразования входных данных.
Определившись в общих чертах, что собой представляет нейронная сеть, можно выделить основные типы их классификации. Прежде чем приступить к классификации необходимо ввести одно уточнение. Каждая сеть имеет первый слой нейронов, который называется входным.
Он не выполняет никаких вычислений и преобразований, его задача состоит только в одном: принять и распределить по остальным нейронам входные сигналы. Это единственный слой, который является общим для всех типов нейронных сетей, дальнейшая их структура и является критерием для основного деления.
- Однослойная нейронная сеть. Это структура взаимодействия нейронов, при которой после попадания входных данных в первый входной слой сразу передаётся в слой выхода конечного результата. При этом первый входной слой не считается, так как он не выполняет никаких действий, кроме приёма и распределения, об этом уже было сказано выше. А второй слой производит все нужные вычисления и обработки и сразу выдаёт конечный результат. Входные нейроны объединены с основным слоем синапсами, имеющими различный весовой коэффициент, обеспечивающий качество связей.
- Многослойная нейронная сеть. Как понятно из определения, этот вид нейронных сетей помимо входного и выходного слоёв имеет ещё и промежуточные слои. Их количество зависит от степени сложности самой сети. Она в большей степени напоминает структуру биологической нейронной сети. Такие виды сетей были разработаны совсем недавно, до этого все процессы были реализованы с помощью однослойных сетей. Соответственно подобное решение имеет намного больше возможностей, чем её предок. В процессе обработки информации каждый промежуточный слой представляет собой промежуточный этап обработки и распределения информации.
В зависимости от направления распределения информации по синапсам от одного нейрона к другому, можно также классифицировать сети на две категории.
- Сети прямого распространения или однонаправленная, то есть структура, в которой сигнал движется строго от входного слоя к выходному. Движение сигнала в обратном направлении невозможно. Подобные разработки достаточно широко распространены и в настоящий момент с успехом решают такие задачи, как распознавание, прогнозы или кластеризация.
- Сети с обратными связями или рекуррентная. Подобные сети позволяют сигналу двигаться не только в прямом, но и в обратном направлении. Что это даёт? В таких сетях результат выхода может возвращаться на вход исходя из этого, выход нейрона определяется весами и сигналами входа, и дополняется предыдущими выходами, которые снова вернулись на вход. Таким сетям свойственна функция кратковременной памяти, на основании которой сигналы восстанавливаются и дополняются в процессе обработки.
Это не единственные варианты классификации сетей.
Их можно разделить на однородные и гибридные опираясь на типы нейронов, составляющих сеть. А также на гетероассоциативные или автоассоциативные, в зависимости от метода обучения сети, с учителем или без. Также можно классифицировать сети по их назначению.
Где используют нейронные сети?
Нейронные сети используются для решения разнообразных задач. Если рассмотреть задачи по степени сложности, то для решения простейших задач подойдёт обычная компьютерная программа, более  усложнённые задачи, требующие простого прогнозирования или приближенного решения уравнений, используются программы с привлечением статистических методов.
усложнённые задачи, требующие простого прогнозирования или приближенного решения уравнений, используются программы с привлечением статистических методов.
А вот задачи ещё более сложного уровня требуют совсем иного подхода. В частности, это относится к распознаванию образов, речи или сложному прогнозированию. В голове человека подобные процессы происходят неосознанно, то есть, распознавая и запоминая образы, человек не осознаёт, как происходит этот процесс, а соответственно не может его контролировать.
Именно такие задачи помогают решить нейронные сети, то есть то есть они созданы чтобы выполнять процессы, алгоритмы которых неизвестны.
Таким образом, нейронные сети находят широкое применение в следующих областях:
- распознавание, причём это направление в настоящее время самое широкое;
- предсказание следующего шага, эта особенность применима на торгах и фондовых рынках;
- классификация входных данных по параметрам, такую функцию выполняют кредитные роботы, которые способны принять решение в одобрении займа человеку, полагаясь на входной набор разных параметров.
Способности нейросетей делают их очень популярными. Их можно научить многому, например, играть в игры, узнавать определённый голос и так далее. Исходя из того, что искусственные сети строятся по принципу биологических сетей, их можно обучить всем процессам, которые человек выполняет неосознанно.
Что такое нейрон и синапс?
Так что же такое нейрон в разрезе искусственных нейросетей? Под этим понятием подразумевается единица, которая выполняет вычисления. Она получает информацию со входного слоя сети, выполняет с ней простые вычисления и проедает её следующему нейрону.
В составе сети имеются три типа нейронов: входной, скрытый и выходной. Причём если сеть однослойная, то скрытых нейронов она не содержит. Кроме этого, есть разновидность единиц, носящих названия нейрон смещения и контекстный нейрон.
Каждый нейрон имеет два типа данных: входные и выходные. При этом у первого слоя входные данные равны выходным. В остальных случаях на вход нейрона попадает суммарная информация предыдущих слоёв, затем она проходит процесс нормализации, то есть все значения, выпадающие из нужного диапазона, преобразуются функцией активации.
Как уже упоминалось выше, синапс — это связь между нейронами, каждая из которых имеет свою степень веса. Именно благодаря этой особенности входная информация видоизменяется в процессе передачи. В процессе обработки информация, переданная синапсом, с большим показателем веса будет преобладающей.
Получается, что на результат влияют не нейроны, а именно синапсы, дающие определённую совокупность веса входных данных, так как сами нейроны каждый раз выполняют совершенно одинаковые вычисления.
При этом веса выставляются в случайном порядке.
Схема работы нейронной сети
Чтобы представить принцип работы нейронной сети не требуется особых навыков. На входной слой нейронов поступает определённая информация. Она передаётся посредством синапсов следующему слою, при этом каждый синапс имеет свой коэффициент веса, а каждый следующий нейрон может иметь несколько входящих синапсов.
В итоге информация, полученная следующим нейроном, представляет собой сумму всех данных, перемноженных каждый на свой коэффициент веса. Полученное значение подставляется в функцию активации и получается выходная информация, которая передаётся дальше, пока не дойдёт до конечного выхода. Первый запуск сети не даёт верных результатов, так как сеть, ещё не натренированная.
Функция активации применяется для нормализации входных данных. Таких функций много, но можно выделить несколько основных, имеющих наиболее широкое распространение. Их основным отличием является диапазон значений, в котором они работают.
- Линейная функция f(x) = x, самая простая из всех возможных, используется только для тестирования созданной нейронной сети или передачи данных в исходном виде.
- Сигмоид считается самой распространённой функцией активации и имеет вид f(x) = 1 / 1+e-×; при этом диапазон её значений от 0 до 1. Она ещё называется логистической функцией.
- Чтобы охватить и отрицательные значения используют гиперболический тангенс. F(x) = e²× - 1 / e²× + 1 — такой вид имеет эта функция и диапазон который она имеет от -1 до 1. Если нейронная сеть не предусматривает использование отрицательных значений, то использовать её не стоит.
Для того чтобы задать сети данные, которыми она будет оперировать необходимы тренировочные сеты.
Интеграция — это счётчик, который увеличивается с каждым тренировочным сетом.Эпоха — это показатель натренированности нейронной сети, этот показатель увеличивается каждый раз, когда сеть проходит цикл полного набора тренировочных сетов.
Соответственно, чтобы проводить тренировку сети правильно нужно выполнять сеты, последовательно увеличивая показатель эпохи.
В процессе тренировки будут выявляться ошибки. Это процентный показатель расхождения между полученным и желаемым результатом. Этот показатель должен уменьшаться в процессе увеличения показателя эпохи, в противном случае где-то ошибка разработчика.
Что такое нейрон смещения и для чего он нужен?
В нейронных сетях есть ещё один вид нейронов — нейрон смещения. Он отличается от основного вида нейронов тем, что его вход и выход в любом случае равняется единице. При этом входных синапсов такие нейроны не имеют.
Расположение таких нейронов происходит по одному на слой и не более, также они не могут соединяться синапсами друг с другом. Размещать такие нейроны на выходном слое не целесообразно.
 Для чего они нужны? Бывают ситуации, в которых нейросеть просто не сможет найти верное решение из-за того, что нужная точка будет находиться вне пределов досягаемости. Именно для этого и нужны такие нейроны, чтобы иметь возможность сместить область определения.
Для чего они нужны? Бывают ситуации, в которых нейросеть просто не сможет найти верное решение из-за того, что нужная точка будет находиться вне пределов досягаемости. Именно для этого и нужны такие нейроны, чтобы иметь возможность сместить область определения.
То есть вес синапса меняет изгиб графика функции, тогда как нейрон смещения позволяет осуществить сдвиг по оси координат Х, таким образом, чтобы нейросеть смогла захватить область недоступную ей без сдвига. При этом сдвиг может быть осуществлён как вправо, так и влево. Схематически нейроны сдвига обычно не обозначаются, их вес учитывается по умолчанию при расчёте входного значения.
Также нейроны смещения позволят получить результат в том случае, когда все остальные нейроны выдают 0 в качестве выходного параметра. В этом случае независимо от веса синапса на каждый следующий слой будет передаваться именно это значение.
Наличие нейрона смещения позволит исправить ситуацию и получить иной результат. Целесообразность использования нейронов смещения определяется путём тестирования сети с ними и без них и сравнения результатов.
Но важно помнить, что для достижения результатов мало создать нейронную сеть. Её нужно ещё и обучить, что тоже требует особых подходов и имеет свои алгоритмы. Этот процесс сложно назвать простым, так как его реализация требует определённых знаний и усилий.
Всем привет!
Буквально вчера нашел книгу Тарика Рашида «Создай свою нейросеть». Книга является бестселлером (топ 1 продаж) в разделе «Искусственный интеллект». Книга свежая, вышла в прошлом году.
Впечатления от первых разделов замечательные. Одно из лучших введений в сферу нейросетей из всех мною виденных. Книга мне так понравилась, что я решил перевести ее на русский язык и выкладывать сюда в виде статей. Часть материала из книги пойдет на улучшение уже существующих глав, часть на следующие.
Перевел уже два первых раздела 1 главы. Вы можете этих разделов.
Читайте - наслаждайтесь!
1 Глава. Как они работают.
1.1 Легко для меня, тяжело для тебя
Все компьютеры являются калькуляторами в душе. Они умеют очень быстро считать.
Не стоит их в этом упрекать. Они отлично выполняют свою работу: считают цену с учетом скидки, начисляют долговые проценты, рисуют графики по имеющимся данным и так далее.
Даже просмотр телевизора или прослушивание музыки с помощью компьютера представляют собой выполнение огромного количества арифметических операций снова и снова. Это может прозвучать удивительно, но отрисовка каждого кадра изображения из нулей и единиц, полученных через интернет задействует вычисления, которые не сильно сложнее тех задач, которые мы все решали в школе.
Однако, способность компьютера складывать тысячи и миллионы чисел в секунду вовсе не является искусственным интеллектом. Человеку сложно так быстро складывать числа, но согласитесь, что эта работа не требует серьезных интеллектуальных затрат. Надо придерживаться заранее известного алгоритма по складыванию чисел и ничего более. Именно этим и занимаются все компьютеры - придерживаются четкого алгоритма.
С компьютерами все ясно. Теперь давайте поговорим о том, в чем мы хороши по сравнению с ними.
Посмотрите на картинки ниже и определите, что на них изображено:

Вы видите лица людей на первой картинке, морду кошки на второй и дерево на третьей. Вы распознали объекты на этих картинках. Заметьте, что вам хватило лишь взгляда, чтобы безошибочно понять, что на них изображено. Мы редко ошибаемся в таких вещах.
Мы мгновенно и без особого труда воспринимаем огромное количество информации, которое содержат изображения и очень точно определяем объекты на них. А вот для любого компьютера такая задача встанет поперек горла.
У любого компьютера вне зависимости от его сложности и быстроты нет одного важного качества - интеллекта, которым обладает каждый человек.
Но мы хотим научить компьютеры решать подобные задачи, потому что они быстрые и не устают. Искусственный интеллект как раз занимается решением подобного рода задач.
Конечно компьютеры и дальше будут состоять из микросхем. Задача искусственного интеллекта - найти новые алгоритмы работы компьютера, которые позволят решать интеллектуальные задачи. Эти алгоритмы не всегда идеальны, но они решают поставленные задачи и создают впечатление, что компьютер ведет себя как человек.
Ключевые моменты
- Есть задачи легкие для обычных компьютеров, но вызывающие трудности и людей. Например, умножение миллиона чисел друг на друга.
- С другой стороны, существуют не менее важные задачи, которые невероятно сложны для компьютера и не вызывают проблем у людей. Например, распознавание лиц на фотографиях.
1.2 Простая предсказательная машина
Давайте начнем с чего-нибудь очень простого. Дальше мы будет отталкиваться от материала, изученного в этом разделе.
Представьте себе машину, которая получает вопрос, «обдумывает» его и затем выдает ответ. В примере выше вы получали картинку на вход, анализировали ее с помощью мозгов и делали вывод об объекте, который на ней изображен. Выглядит это как-то так:

Компьютеры на самом деле ничего не «обдумывают». Они просто применяют заранее известные арифметические операции. Поэтому давайте будем называть вещи своими именами:

Компьютер принимает какие-то данные на вход, производит необходимые вычисления и выдает готовый результат. Рассмотрим следующий пример. Если на вход компьютеру поступает выражение \(3 \times 4 \) , то оно преобразуется в более простую последовательность сложений. Как итог, получаем результат - 12.

Выглядит не слишком впечатляюще. Это нормально. С помощью этих тривиальных примеров вы увидите идею, которую реализуют нейросети.
Теперь представьте себе машину, которая преобразует километры в мили:

Теперь представьте, что мы не знаем формулу, с помощью которой километры переводятся в мили. Мы знаем только, что зависимость между двумя этими величинами линейная . Это означает, что если мы в два раза увеличим дистанцию в милях, то дистанция в километрах тоже увеличится в два раза. Это интуитивно понятно. Вселенная была бы очень странной, если бы это правило не выполнялось.
Линейная зависимость между километрами и милями дает нам подсказку, в какой форме надо преобразовывать одну величину в другую. Мы можем представить эту зависимость так:
\[ \text{мили} = \text{километры} \times C \]
В выражении выше \(C \) выступает в роли некоторого постоянного числа - константы. Пока мы не знаем, чему равно \(C \) .
Единственное, что нам известно - несколько заранее верно отмеренных расстояний в километрах и милях.
И как же узнать значение \(C \) ? А давайте просто придумаем случайное число и скажем, что ему-то и равна наша константа. Пусть \(C = 0.5 \) . Что же произойдет?

Принимая, что \(C = 0.5 \) мы из 100 километров получаем 50 миль. Это отличный результат принимая во внимания тот факт, что \(C = 0.5 \) мы выбрали совершенно случайно! Но мы знаем, что наш ответ не совсем верен, потому что согласно таблице верных замеров мы должны были получить 62.137 мили.
Мы промахнулись на 12.137 миль. Это наша погрешность - разница между полученным ответом и заранее известным правильным результатом, который в данном случае мы имеем в таблице.
\[ \begin{gather*} \text{погрешность} = \text{правильное значение} — \text{полученный ответ} \\ = 62.137 — 50 \\ = 12.137 \end{gather*} \]

Вновь смотрим на погрешность. Полученное расстояние короче на 12.137. Так как формула по переводу километров в мили линейная (\(\text{мили} = \text{километры} \times C \) ), то увеличение значения \(C \) увеличит и выходной результат в милях.
Давайте теперь примем, что \(C = 0.6 \) и посмотрим, что произойдет.
Так как \(C=0.6 \) , то для 100 километров имеем \(100 \times 0.6 = 60 \) миль. Это гораздо лучше предыдущей попытки (в тот раз было 50 миль)! Теперь наша погрешность очень мала - всего 2.137 мили. Вполне себе точный результат.

Теперь обратите внимание на то, как мы использовали полученную погрешность для корректировки значения константы \(C \) . Нам нужно было увеличить выходное число миль и мы немного увеличили значение \(C \) . Заметьте, что мы не используем алгебру для получения точного значения \(C \) , а ведь мы могли бы. Почему? Потому что на свете полно задач, которые не имеют простой математической связи между полученным входом и выдаваемым результатом.
Именно для задач, которые практически не решаются простым подсчетом нам и нужны такие изощренные штуки, как нейронные сети.

Боже мой! Мы хватанули слишком много и превысили правильный результат. Наша предыдущая погрешность равнялась 2.137, а теперь она равна -7.863. Минус означает, что наш результат оказался больше правильного ответа, так как погрешность вычисляется как правильный ответ — (минус) полученный ответ.
Получается, что при \(C=0.6 \) мы имеем гораздо более точный выход. На этом можно было бы и закончить. Но давайте все же увеличим \(C \) , но не сильно! Пусть \(C=0.61 \) .

Так-то лучше! Наша машина выдает 61 милю, что всего на 1.137 милю меньше, чем правильный ответ (62.137).
Из этой ситуации с превышением правильного ответа надо вынести важный урок. По мере приближения к правильному ответу параметры машины стоит менять все слабее и слабее. Это поможет избежать неприятных ситуаций, которые приводят к превышению правильного ответа.
Величина нашей корректировки \(C \) зависит от погрешности. Чем больше наша погрешность, тем более сильно мы меняем значение \(C \) . Но когда погрешность становиться маленькой, необходимо менять \(C \) по чуть-чуть. Логично, не так ли?
Верьте или нет, но только что вы поняли самую суть работы нейронных сетей. Мы тренируем «машины» постепенно выдавать все более и более точный результат.
Важно понимать и то, как мы решали эту задачу. Мы не решали ее в один заход, хотя в данном случае так можно было бы поступить. Вместо этого, мы приходили к правильному ответу по шагам так, что с каждым шагом наши результаты становились лучше.
Не правда ли объяснения очень простые и понятные? Лично я не встречал более лаконичного способа объяснить, что такое нейросети.
Если вам что-то непонятно, задавайте вопросы на форуме.
Мне важно ваше мнение - оставляйте комментарии 🙂








